Learning from Failures¶
Given the many executions we can generate, it is only natural that these executions would also be subject to machine learning in order to learn which features of the input (or the execution) would be associated with failures.
In this chapter, we study the Alhazen approach, one of the first of this kind.
Alhazen by Kampmann et al. \cite{Kampmann2020} automatically learns the associations between the failure of a program and features of the input data, say "The error occurs whenever the <expr> element is negative"
This chapter is based on an Alhazen implementation contributed by Martin Eberlein of TU Berlin. Thanks a lot, Martin!
# from bookutils import YouTubeVideo
# YouTubeVideo("w4u5gCgPlmg")
Prerequisites
- This chapter extends the ideas from the chapter on Generalizing Failure Circumstances.
Synopsis¶
To use the code provided in this chapter, write
>>> from debuggingbook.Alhazen import <identifier>
and then make use of the following features.
This chapter provides an implementation of the Alhazen approach \cite{Kampmann2020}, which trains machine learning classifiers from input features.
Given a test function, a grammar, and a set of inputs, the Alhazen class produces a decision tree that characterizes failure circumstances:
>>> alhazen = Alhazen(sample_runner, CALC_GRAMMAR, initial_sample_list,
>>> max_iterations=20)
>>> alhazen.run()
The final decision tree can be accessed using last_tree():
>>> # alhazen.last_tree()
We can visualize the resulting decision tree using Alhazen.show_decision_tree():
>>> alhazen.show_decision_tree()

A decision tree is read from top to bottom. Decision nodes (with two children) come with a predicate on top. This predicate is either
- numeric, such as
<value> > 20, indicating the numeric value of the given symbol, or - existential, such as
<digit> == '1', which has a negative value when False, and a positive value when True.
If the predicate evaluates to True, follow the left path; if it evaluates to False, follow the right path.
A leaf node (no children) will give you the final decision class = BUG or class = NO_BUG.
So if the predicate states <function> == 'sqrt' <= 0.5, this means that
- If the function is not
sqrt(the predicate<function> == 'sqrt'is negative, see above, and hence less than 0.5), follow the left (True) path. - If the function is
sqrt(the predicate<function> == 'sqrt'is positive), follow the right (False) path.
The samples field shows the number of sample inputs that contributed to this decision.
The gini field (aka Gini impurity) indicates how many samples fall into the displayed class (BUG or NO_BUG).
A gini value of 0.0 means purity - all samples fall into the displayed class.
The saturation of nodes also indicates purity – the higher the saturation, the higher the purity.
There is also a text version available, with much fewer (but hopefully still essential) details:
>>> print(alhazen.friendly_decision_tree())
if <lead-digit> <= 4.5000:
if <function> == 'sqrt':
if <value> <= 42.7000:
if <term> <= -11.7870:
BUG
else:
NO_BUG
else:
NO_BUG
else:
NO_BUG
else:
NO_BUG
In both representations, we see that the present failure is associated with a negative value for the sqrt function and precise boundaries for its value.
In fact, the error conditions are given in the source code:
>>> import inspect
>>> print(inspect.getsource(task_sqrt))
def task_sqrt(x):
"""Computes the square root of x, using the Newton-Raphson method"""
if x <= -12 and x >= -42:
x = 0 # Guess where the bug is :-)
else:
x = 1
x = max(x, 0)
approx = None
guess = x / 2
while approx != guess:
approx = guess
guess = (approx + x / approx) / 2
return approx
Try out Alhazen on your own code and your own examples!
Machine Learning for Automated Debugging¶
When diagnosing why a program fails, the first step is to determine the circumstances under which the program fails. In past chapters, we have examined approaches that correlate execution features with failures as well as tools that systematically generate inputs to reduce failure-inducing inputs or generalize failure circumstances. In this chapter, we will go one step further and make use of full-fledged machine learning to identify failure circumstances (and causes).
The Alhazen Approach¶
In 2020, Kampmann et al. \cite{Kampmann2020} presented one of the first approaches to automatically learn circumstances of (failing) program behavior. Their approach associates the program’s failure with the syntactical features of the input data, allowing them to learn and extract the properties that result in the specific behavior.
Their reference implementation Alhazen can generate a diagnosis and explain why, for instance, a particular bug occurs. Alhazen forms a hypothetical model based on the observed inputs. Additional test inputs are generated and executed to refine or refute the hypothesis, eventually obtaining a prediction model of the circumstances of why the behavior in question takes place.
The tool is named after Ḥasan Ibn al-Haytham (latinized name: Alhazen). Often referred to as the "Father of modern optics", Ibn al-Haytham made significant contributions to the principles of optics and visual perception. Most notably, he was an early proponent of the concept that a hypothesis must be supported by experiments, and thus one of the inventors of the scientific method, the key process in the Alhazen tool.
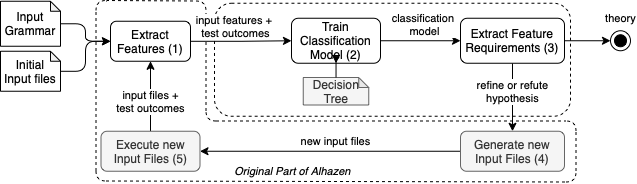
Let us give a high-level description of how Alhazen works, illustrated above.
Alhazen is given an input grammar and a number of input files (whose format is given by the grammar), and produces a decision tree – a machine learning model that explains under which circumstances the program fails.
Alhazen determines and refines these decision trees in five steps:
- For each input file, Alhazen extracts a number of input features that apply.
These input features are predicates over the individual elements of the input grammar, such as
<expr> > 0(an<expr>element is larger than zero) orexists(<minus-sign>)(the input contains a minus sign). - The test outcomes of the input files label these input files as buggy or non-buggy. From the respective input features and the labels, Alhazen trains a decision tree that associates these features with the labels - that is, the decision tree explains which features lead to buggy or non-buggy.
- As it is typically trained on few samples only, the initial classification model may be imprecise.
Hence, Alhazen extracts further requirements for additional test cases that may help in increasing precision, such as
<digit> == '6'(we need more inputs in which the<digit>field has a value of6.) - Satisfying these requirements, Alhazen then generates additional inputs...
- ...which it executes, thus again labeling them as buggy or non-buggy. From the new inputs, we can again extract the features, and repeat the cycle.
The whole process keeps on refining decision trees with more and more inputs. Eventually, the decision trees are supposed to be precise enough that they can become theory - that is, an explanation of why the program fails with high predictive power for future inputs.
The Alhazen process thus automates the scientific method of debugging:
- making initial observations (Steps 1 and 2),
- coming up with hypotheses that explain the observations (Step 3),
- designing experiments to further support or refute the hypotheses (Steps 4 and 5),
- and repeating the entire process until we have a predicting theory on why the program fails.
Structure of this Chapter¶
In the remainder of this chapter, we will first introduce grammars.
We then explore and implement the individual steps of Alhazen:
- Step 1: Extracting Features
- Step 2: Train Classification Model
- Step 3: Extract Feature Requirements
- Step 4: Generating New Samples
- Step 5: Executing New Inputs
After this is done, we can compose all these into a single Alhazen class and run it on a sample input.
If you want to see Alhazen in action first (before going into all the details, check out the sample run.)
Inputs and Grammars¶
Alhazen heavily builds on grammars as a means to decompose inputs into individual elements, such that it can reason about these elements, and also generate new ones automatically.
To work with grammars, we use the framework provided by The Fuzzing Book. For a more detailed description of Grammars and how to use them for production, have a look at the chapter "Fuzzing with Grammars"
Let us build a simple grammar for a calculator. The calculator code is listed below.
"""
This file contains the code under test for the example bug.
The sqrt() method fails on x <= 0.
"""
def task_sqrt(x):
"""Computes the square root of x, using the Newton-Raphson method"""
if x <= -12 and x >= -42:
x = 0 # Guess where the bug is :-)
else:
x = 1
x = max(x, 0)
approx = None
guess = x / 2
while approx != guess:
approx = guess
guess = (approx + x / approx) / 2
return approx
def task_tan(x):
return rtan(x)
def task_cos(x):
return rcos(x)
def task_sin(x):
return rsin(x)
The language consists of functions (<function>) that are being invoked on a numerical value (<term>).
CALC_GRAMMAR: Grammar = {
"<start>":
["<function>(<term>)"],
"<function>":
["sqrt", "tan", "cos", "sin"],
"<term>": ["-<value>", "<value>"],
"<value>":
["<integer>.<digits>",
"<integer>"],
"<integer>":
["<lead-digit><digits>", "<digit>"],
"<digits>":
["<digit><digits>", "<digit>"],
"<lead-digit>": # First digit cannot be zero
["1", "2", "3", "4", "5", "6", "7", "8", "9"],
"<digit>":
["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"],
}
We see that the CALC_GRAMMAR consists of several production rules. The calculator subject will only accept inputs that conform to this grammar definition.
Let us load two initial input samples:
sqrt(-16)sqrt(4)
# Load initial input files
initial_sample_list = ['sqrt(-16)', 'sqrt(4)']
Let's execute our two input samples and observe the calculator's behavior.
We implement the function sample_runner(sample) that lets us execute the calculator for a single sample. sample_runner(sample) returns an OracleResult for the sample.
class OracleResult(Enum):
BUG = "BUG"
NO_BUG = "NO_BUG"
UNDEF = "UNDEF"
def __str__(self):
return self.value
SUBJECT = "calculator"
def sample_runner(sample):
testcode = sample
try:
# Simply execute the calculator code, with the functions replaced
exec(testcode, {"sqrt": task_sqrt, "tan": task_tan, "sin": task_sin, "cos": task_cos}, {})
return OracleResult.NO_BUG
except ZeroDivisionError:
return OracleResult.BUG
except Exception as e:
print(e, file=sys.stderr)
return OracleResult.UNDEF
Let's test the function:
sample = "sqrt(-16)"
sample_runner(sample)
<OracleResult.BUG: 'BUG'>
As expected, the sample sqrt(-16) triggers the calculator bug. Let's try some more samples:
assert sample_runner("sqrt(-23)") == OracleResult.BUG
assert sample_runner("sqrt(44)") == OracleResult.NO_BUG
assert sample_runner("cos(-9)") == OracleResult.NO_BUG
What happens if we parse inputs to calculator that do not conform to its input format?
sample_runner("undef_function(QUERY)")
name 'undef_function' is not defined
<OracleResult.UNDEF: 'UNDEF'>
The function sample_runner(sample) returns an OracleResult.UNDEF whenever the runner is not able to execute the sample.
Finally, we provide the function execute_samples(sample_list) that obtains the oracle/label for a list of samples.
We use the pandas module to place these in a data frame.
# Executes a list of samples and return the execution outcome (label)
# The function returns a pandas dataframe
def execute_samples(sample_list):
data = []
for sample in sample_list:
result = sample_runner(sample)
data.append({"oracle": result })
return pandas.DataFrame.from_records(data)
Let us define a bigger list of samples to execute...
sample_list = ["sqrt(-20)", "cos(2)", "sqrt(-100)", "undef_function(foo)"]
... and obtain the execution outcome
labels = execute_samples(sample_list)
labels
name 'undef_function' is not defined
| oracle | |
|---|---|
| 0 | BUG |
| 1 | NO_BUG |
| 2 | NO_BUG |
| 3 | UNDEF |
We can combine these with the sample_list:
for i, row in enumerate(labels['oracle']): print(sample_list[i].ljust(30) + str(row))
sqrt(-20) BUG cos(2) NO_BUG sqrt(-100) NO_BUG undef_function(foo) UNDEF
We can remove the undefined input samples like this:
clean_data = labels.drop(labels[labels.oracle.astype(str) == "UNDEF"].index)
clean_data
| oracle | |
|---|---|
| 0 | BUG |
| 1 | NO_BUG |
| 2 | NO_BUG |
We can combine sample and labels by iterating over the obtained oracle:
oracle = execute_samples(sample_list)
for i, row in enumerate(oracle['oracle']):
print(sample_list[i].ljust(30) + str(row))
sqrt(-20) BUG cos(2) NO_BUG sqrt(-100) NO_BUG undef_function(foo) UNDEF
name 'undef_function' is not defined
We observe that the sample sqrt(-16) triggers a bug in the calculator, whereas the sample sqrt(4) does not show unusual behavior. Of course, we want to know why the sample fails the program. In a typical use case, the developers of the calculator program would now try other input samples and evaluate if similar inputs also trigger the program's failure. Let's try some more input samples; maybe we can refine our understanding of why the calculator crashes:
Our guesses - maybe the failure is also in the cos() or tan() function?
guess_samples = ['cos(-16)', 'tan(-16)', 'sqrt(-100)', 'sqrt(-20.23412431234123)']
Let's obtain the execution outcome for each of our guesses:
guess_oracle = execute_samples(guess_samples)
Here come the results:
for i, row in enumerate(guess_oracle['oracle']):
print(guess_samples[i].ljust(30) + str(row))
cos(-16) NO_BUG tan(-16) NO_BUG sqrt(-100) NO_BUG sqrt(-20.23412431234123) BUG
It looks like the failure only occurs in the sqrt() function, however, only for specific x values.
We could now try other values for x and repeat the process.
However, this would be highly time-consuming and not an efficient debugging technique for a larger and more complex test subject.
Wouldn't it be great if there was a tool that automatically does this for us? And this is exactly what Alhazen is there for. It helps us explain why specific input features cause a program to fail.
Step 1: Extracting Features¶
In this section, we are concerned with the problem of extracting semantic features from inputs. In particular, Alhazen defines various features based on the input grammar, such as existence and numeric interpretation. These features are then extracted from the parse trees of the inputs (see Section 3 of \cite{Kampmann2020} for more details).
The implementation of the feature extraction module consists of the following three tasks:
- Implementation of individual feature classes, whose instances allow deriving specific feature values from inputs
- Extraction of features from the grammar through instantiation of the aforementioned feature classes
- Computation of feature vectors from a set of inputs, which will then be used as input for the decision tree
Internal and "Friendly" Feature Names¶
We use two kinds of names for features:
- internal names have the form
<SYMBOL>@Nand refer to theN-th expansion of symbol (starting with 0). InCALC_GRAMMAR, for instance,<function>@0refers to the expansion of<function>to"sqrt" - friendly names are more user-friendly (hence the name).
The above feature
<function>@0has the "friendly" name<function> == "sqrt".
We use internal names in all our interaction with the machine learner, as they are unambiguous and do not contain whitespace. When showing the final results, we switch to "friendly" names.
Implementing Feature Classes¶
class Feature(ABC):
'''
The abstract base class for grammar features.
Args:
name : A unique identifier name for this feature. Should not contain Whitespaces.
e.g., 'type(<feature>@1)'
rule : The production rule (e.g., '<function>' or '<value>').
key : The feature key (e.g., the chosen alternative or rule itself).
'''
def __init__(self, name: str, rule: str, key: str, /,
friendly_name: str = None) -> None:
self.name = name
self.rule = rule
self.key = key
self._friendly_name = friendly_name or name
super().__init__()
def __repr__(self) -> str:
'''Returns a printable string representation of the feature.'''
return self.name_rep()
@abstractmethod
def name_rep(self) -> str:
pass
def friendly_name(self) -> str:
return self._friendly_name
@abstractmethod
def get_feature_value(self, derivation_tree) -> float:
'''Returns the feature value for a given derivation tree of an input.'''
pass
def replace(self, new_key: str) -> 'Feature':
'''Returns a new feature with the same name but a different key.'''
return self.__class__(self.name, self.rule, new_key)
class ExistenceFeature(Feature):
'''
This class represents existence features of a grammar. Existence features indicate
whether a particular production rule was used in the derivation sequence of an input.
For a given production rule P -> A | B, a production existence feature for P and
alternative existence features for each alternative (i.e., A and B) are defined.
name : A unique identifier name for this feature. Should not contain Whitespaces.
e.g., 'exist(<digit>@1)'
rule : The production rule.
key : The feature key, equal to the rule attribute for production features,
or equal to the corresponding alternative for alternative features.
'''
def __init__(self, name: str, rule: str, key: str,
friendly_name: str = None) -> None:
super().__init__(name, rule, key, friendly_name=friendly_name)
def name_rep(self) -> str:
if self.rule == self.key:
return f"exists({self.rule})"
else:
return f"exists({self.rule} == {self.key})"
def get_feature_value(self, derivation_tree) -> float:
'''Returns the feature value for a given derivation tree of an input.'''
raise NotImplementedError
def get_feature_value(self, derivation_tree: DerivationTree) -> float:
'''Counts the number of times this feature was matched in the derivation tree.'''
(node, children) = derivation_tree
# The local match count (1 if the feature is matched for the current node, 0 if not)
count = 0
# First check if the current node can be matched with the rule
if node == self.rule:
# Production existance feature
if self.rule == self.key:
count = 1
# Production alternative existance feature
# We compare the children of the expansion with the actual children
else:
expansion_children = list(map(lambda x: x[0], expansion_to_children(self.key)))
node_children = list(map(lambda x: x[0], children))
if expansion_children == node_children:
count= 1
# Recursively compute the counts for all children and return the sum for the whole tree
for child in children:
count = max(count, self.get_feature_value(child))
return count
class NumericInterpretation(Feature):
'''
This class represents numeric interpretation features of a grammar. These features
are defined for productions that only derive words composed of the characters
[0-9], '.', and '-'. The returned feature value corresponds to the maximum
floating-point number interpretation of the derived words of a production.
name : A unique identifier name for this feature. Should not contain Whitespaces.
e.g., 'num(<integer>)'
rule : The production rule.
'''
def __init__(self, name: str, rule: str, /,
friendly_name: str = None) -> None:
super().__init__(name, rule, rule, friendly_name=friendly_name)
def name_rep(self) -> str:
return f"num({self.key})"
def get_feature_value(self, derivation_tree) -> float:
'''Returns the feature value for a given derivation tree of an input.'''
raise NotImplementedError
def get_feature_value(self, derivation_tree: DerivationTree) -> float:
'''Determines the maximum float of this feature in the derivation tree.'''
(node, children) = derivation_tree
value = float('nan')
if node == self.rule:
try:
#print(self.name, float(tree_to_string(derivation_tree)))
value = float(tree_to_string(derivation_tree))
except ValueError:
#print(self.name, float(tree_to_string(derivation_tree)), "err")
pass
# Return maximum value encountered in tree, ignoring all NaNs
tree_values = [value] + [self.get_feature_value(c) for c in children]
if all(numpy.isnan(tree_values)):
return value
else:
return numpy.nanmax(tree_values)
Extracting Feature Sets from Grammars¶
def extract_existence_features(grammar: Grammar) -> List[ExistenceFeature]:
'''
Extracts all existence features from the grammar and returns them as a list.
grammar : The input grammar.
'''
features = []
for rule in grammar:
# add the rule
features.append(ExistenceFeature(f"exists({rule})", rule, rule))
# add all alternatives
for count, expansion in enumerate(grammar[rule]):
name = f"exists({rule}@{count})"
friendly_name = f"{rule} == {repr(expansion)}"
feature = ExistenceFeature(name, rule, expansion,
friendly_name=friendly_name)
features.append(feature)
return features
# Regex for non-terminal symbols in expansions
RE_NONTERMINAL = re.compile(r'(<[^<> ]*>)')
def extract_numeric_features(grammar: Grammar) -> List[NumericInterpretation]:
'''
Extracts all numeric interpretation features from the grammar and returns them as a list.
grammar : The input grammar.
'''
features = []
# Mapping from non-terminals to derivable terminal chars
derivable_chars = defaultdict(set)
for rule in grammar:
for expansion in grammar[rule]:
# Remove non-terminal symbols and whitespace from expansion
terminals = re.sub(RE_NONTERMINAL, '', expansion).replace(' ', '')
# Add each terminal char to the set of derivable chars
for c in terminals:
derivable_chars[rule].add(c)
# Repeatedly update the mapping until convergence
while True:
updated = False
for rule in grammar:
for r in reachable_nonterminals(grammar, rule):
before = len(derivable_chars[rule])
derivable_chars[rule].update(derivable_chars[r])
after = len(derivable_chars[rule])
# Set of derivable chars was updated
if after > before:
updated = True
if not updated:
break
numeric_chars = set(['0','1','2','3','4','5','6','7','8','9','.','-'])
for key in derivable_chars:
# Check if derivable chars contain only numeric chars
if len(derivable_chars[key] - numeric_chars) == 0:
name = f"num({key})"
friendly_name = f"{key}"
features.append(NumericInterpretation(f"num({key})", key,
friendly_name=friendly_name))
return features
def extract_all_features(grammar: Grammar) -> List[Feature]:
return (extract_existence_features(grammar)
+ extract_numeric_features(grammar))
Here are all the features from our calculator grammar:
extract_all_features(CALC_GRAMMAR)
[exists(<start>), exists(<start> == <function>(<term>)), exists(<function>), exists(<function> == sqrt), exists(<function> == tan), exists(<function> == cos), exists(<function> == sin), exists(<term>), exists(<term> == -<value>), exists(<term> == <value>), exists(<value>), exists(<value> == <integer>.<digits>), exists(<value> == <integer>), exists(<integer>), exists(<integer> == <lead-digit><digits>), exists(<integer> == <digit>), exists(<digits>), exists(<digits> == <digit><digits>), exists(<digits> == <digit>), exists(<lead-digit>), exists(<lead-digit> == 1), exists(<lead-digit> == 2), exists(<lead-digit> == 3), exists(<lead-digit> == 4), exists(<lead-digit> == 5), exists(<lead-digit> == 6), exists(<lead-digit> == 7), exists(<lead-digit> == 8), exists(<lead-digit> == 9), exists(<digit>), exists(<digit> == 0), exists(<digit> == 1), exists(<digit> == 2), exists(<digit> == 3), exists(<digit> == 4), exists(<digit> == 5), exists(<digit> == 6), exists(<digit> == 7), exists(<digit> == 8), exists(<digit> == 9), num(<term>), num(<value>), num(<lead-digit>), num(<digit>), num(<digits>), num(<integer>)]
The friendly representation is a bit more concise and more readable:
[f.friendly_name() for f in extract_all_features(CALC_GRAMMAR)]
['exists(<start>)', "<start> == '<function>(<term>)'", 'exists(<function>)', "<function> == 'sqrt'", "<function> == 'tan'", "<function> == 'cos'", "<function> == 'sin'", 'exists(<term>)', "<term> == '-<value>'", "<term> == '<value>'", 'exists(<value>)', "<value> == '<integer>.<digits>'", "<value> == '<integer>'", 'exists(<integer>)', "<integer> == '<lead-digit><digits>'", "<integer> == '<digit>'", 'exists(<digits>)', "<digits> == '<digit><digits>'", "<digits> == '<digit>'", 'exists(<lead-digit>)', "<lead-digit> == '1'", "<lead-digit> == '2'", "<lead-digit> == '3'", "<lead-digit> == '4'", "<lead-digit> == '5'", "<lead-digit> == '6'", "<lead-digit> == '7'", "<lead-digit> == '8'", "<lead-digit> == '9'", 'exists(<digit>)', "<digit> == '0'", "<digit> == '1'", "<digit> == '2'", "<digit> == '3'", "<digit> == '4'", "<digit> == '5'", "<digit> == '6'", "<digit> == '7'", "<digit> == '8'", "<digit> == '9'", '<term>', '<value>', '<lead-digit>', '<digit>', '<digits>', '<integer>']
Extracting Feature Values from Inputs¶
This is a rather slow implementation. For many grammars with many syntactically features, the feature collection can be optimized.
def collect_features(sample_list: List[str],
grammar: Grammar) -> pandas.DataFrame:
data = []
# parse grammar and extract features
all_features = extract_all_features(grammar)
# iterate over all samples
for sample in sample_list:
parsed_features = {}
parsed_features["sample"] = sample
# initate dictionary
for feature in all_features:
parsed_features[feature.name] = 0
# Obtain the parse tree for each input file
earley = EarleyParser(grammar)
for tree in earley.parse(sample):
for feature in all_features:
parsed_features[feature.name] = feature.get_feature_value(tree)
data.append(parsed_features)
return pandas.DataFrame.from_records(data)
sample_list = ["sqrt(-900)", "sin(24)", "cos(-3.14)"]
collect_features(sample_list, CALC_GRAMMAR)
| sample | exists(<start>) | exists(<start>@0) | exists(<function>) | exists(<function>@0) | exists(<function>@1) | exists(<function>@2) | exists(<function>@3) | exists(<term>) | exists(<term>@0) | ... | exists(<digit>@6) | exists(<digit>@7) | exists(<digit>@8) | exists(<digit>@9) | num(<term>) | num(<value>) | num(<lead-digit>) | num(<digit>) | num(<digits>) | num(<integer>) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | sqrt(-900) | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | ... | 0 | 0 | 0 | 0 | -900.00 | 900.00 | 9.0 | 0.0 | 0.0 | 900.0 |
| 1 | sin(24) | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | ... | 0 | 0 | 0 | 0 | 24.00 | 24.00 | 2.0 | 4.0 | 4.0 | 24.0 |
| 2 | cos(-3.14) | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | ... | 0 | 0 | 0 | 0 | -3.14 | 3.14 | NaN | 4.0 | 14.0 | 3.0 |
3 rows × 47 columns
# TODO: handle multiple trees
def compute_feature_values(sample: str, grammar: Grammar, features: List[Feature]) -> Dict[str, float]:
'''
Extracts all feature values from an input.
sample : The input.
grammar : The input grammar.
features : The list of input features extracted from the grammar.
'''
earley = EarleyParser(CALC_GRAMMAR)
features = {}
for tree in earley.parse(sample):
for feature in extract_all_features(CALC_GRAMMAR):
features[feature.name_rep()] = feature.get_feature_value(tree)
return features
all_features = extract_all_features(CALC_GRAMMAR)
for sample in sample_list:
print(f"Features of {sample}:")
features = compute_feature_values(sample, CALC_GRAMMAR, all_features)
for feature, value in features.items():
print(f" {feature}: {value}")
Features of sqrt(-900):
exists(<start>): 1
exists(<start> == <function>(<term>)): 1
exists(<function>): 1
exists(<function> == sqrt): 1
exists(<function> == tan): 0
exists(<function> == cos): 0
exists(<function> == sin): 0
exists(<term>): 1
exists(<term> == -<value>): 1
exists(<term> == <value>): 0
exists(<value>): 1
exists(<value> == <integer>.<digits>): 0
exists(<value> == <integer>): 1
exists(<integer>): 1
exists(<integer> == <lead-digit><digits>): 1
exists(<integer> == <digit>): 0
exists(<digits>): 1
exists(<digits> == <digit><digits>): 1
exists(<digits> == <digit>): 1
exists(<lead-digit>): 1
exists(<lead-digit> == 1): 0
exists(<lead-digit> == 2): 0
exists(<lead-digit> == 3): 0
exists(<lead-digit> == 4): 0
exists(<lead-digit> == 5): 0
exists(<lead-digit> == 6): 0
exists(<lead-digit> == 7): 0
exists(<lead-digit> == 8): 0
exists(<lead-digit> == 9): 1
exists(<digit>): 1
exists(<digit> == 0): 1
exists(<digit> == 1): 0
exists(<digit> == 2): 0
exists(<digit> == 3): 0
exists(<digit> == 4): 0
exists(<digit> == 5): 0
exists(<digit> == 6): 0
exists(<digit> == 7): 0
exists(<digit> == 8): 0
exists(<digit> == 9): 0
num(<term>): -900.0
num(<value>): 900.0
num(<lead-digit>): 9.0
num(<digit>): 0.0
num(<digits>): 0.0
num(<integer>): 900.0
Features of sin(24):
exists(<start>): 1
exists(<start> == <function>(<term>)): 1
exists(<function>): 1
exists(<function> == sqrt): 0
exists(<function> == tan): 0
exists(<function> == cos): 0
exists(<function> == sin): 1
exists(<term>): 1
exists(<term> == -<value>): 0
exists(<term> == <value>): 1
exists(<value>): 1
exists(<value> == <integer>.<digits>): 0
exists(<value> == <integer>): 1
exists(<integer>): 1
exists(<integer> == <lead-digit><digits>): 1
exists(<integer> == <digit>): 0
exists(<digits>): 1
exists(<digits> == <digit><digits>): 0
exists(<digits> == <digit>): 1
exists(<lead-digit>): 1
exists(<lead-digit> == 1): 0
exists(<lead-digit> == 2): 1
exists(<lead-digit> == 3): 0
exists(<lead-digit> == 4): 0
exists(<lead-digit> == 5): 0
exists(<lead-digit> == 6): 0
exists(<lead-digit> == 7): 0
exists(<lead-digit> == 8): 0
exists(<lead-digit> == 9): 0
exists(<digit>): 1
exists(<digit> == 0): 0
exists(<digit> == 1): 0
exists(<digit> == 2): 0
exists(<digit> == 3): 0
exists(<digit> == 4): 1
exists(<digit> == 5): 0
exists(<digit> == 6): 0
exists(<digit> == 7): 0
exists(<digit> == 8): 0
exists(<digit> == 9): 0
num(<term>): 24.0
num(<value>): 24.0
num(<lead-digit>): 2.0
num(<digit>): 4.0
num(<digits>): 4.0
num(<integer>): 24.0
Features of cos(-3.14):
exists(<start>): 1
exists(<start> == <function>(<term>)): 1
exists(<function>): 1
exists(<function> == sqrt): 0
exists(<function> == tan): 0
exists(<function> == cos): 1
exists(<function> == sin): 0
exists(<term>): 1
exists(<term> == -<value>): 1
exists(<term> == <value>): 0
exists(<value>): 1
exists(<value> == <integer>.<digits>): 1
exists(<value> == <integer>): 0
exists(<integer>): 1
exists(<integer> == <lead-digit><digits>): 0
exists(<integer> == <digit>): 1
exists(<digits>): 1
exists(<digits> == <digit><digits>): 1
exists(<digits> == <digit>): 1
exists(<lead-digit>): 0
exists(<lead-digit> == 1): 0
exists(<lead-digit> == 2): 0
exists(<lead-digit> == 3): 0
exists(<lead-digit> == 4): 0
exists(<lead-digit> == 5): 0
exists(<lead-digit> == 6): 0
exists(<lead-digit> == 7): 0
exists(<lead-digit> == 8): 0
exists(<lead-digit> == 9): 0
exists(<digit>): 1
exists(<digit> == 0): 0
exists(<digit> == 1): 1
exists(<digit> == 2): 0
exists(<digit> == 3): 1
exists(<digit> == 4): 1
exists(<digit> == 5): 0
exists(<digit> == 6): 0
exists(<digit> == 7): 0
exists(<digit> == 8): 0
exists(<digit> == 9): 0
num(<term>): -3.14
num(<value>): 3.14
num(<lead-digit>): nan
num(<digit>): 4.0
num(<digits>): 14.0
num(<integer>): 3.0
Step 2: Train Classification Model¶
Now that we have all the input features and the test outcomes, we can start training a machine learner from these. Although other machine learning models have much higher accuracy, we use decision trees as machine learning models because they are easy to interpret by humans. This is crucial as it will be these very same humans that have to fix the code.
Before we start with our actual implementation, let us first illustrate how training such a classifier works, again using our calculator as an example.
Decision Trees¶
We will use scikit-learn as the machine learning library.
The DecisionTreeClassifier can then learn the syntactical input features that are responsible for the bug-triggering behavior of our Calculator.
First, we transform the individual input features (represented as Python dictionaries) into a NumPy array.
For this example, we use the following four features (function-sqrt, function-cos, function-sin, number) to describe an input feature.
(Please note that this is an extremely reduced example; this is not the complete list of features that should be extracted from the CALC_GRAMMAR Grammar.)
The features function-sqrt, function-cos, function-sin state whether the function sqrt, cos, or sin was used.
A 1 is given if the sample contains the respective function, otherwise the feature contains a 0.
For each <function>(x), the number feature describes which value was used for x. For instance, the first input sqrt(-900) corresponds to 'function-sqrt': 1 and 'number': -900.
# Features for each input, one dict per input
features = [
{'function-sqrt': 1, 'function-cos': 0, 'function-sin': 0, 'number': -900}, # sqrt(-900)
{'function-sqrt': 0, 'function-cos': 1, 'function-sin': 0, 'number': 300}, # cos(300)
{'function-sqrt': 1, 'function-cos': 0, 'function-sin': 0, 'number': -1}, # sqrt(-1)
{'function-sqrt': 0, 'function-cos': 1, 'function-sin': 0, 'number': -10}, # cos(-10)
{'function-sqrt': 0, 'function-cos': 0, 'function-sin': 1, 'number': 36}, # sin(36)
{'function-sqrt': 0, 'function-cos': 0, 'function-sin': 1, 'number': -58}, # sin(-58)
{'function-sqrt': 1, 'function-cos': 0, 'function-sin': 0, 'number': 27}, # sqrt(27)
]
We define a list of labels (or oracles) that state whether the specific input file resulted in a bug or not. We use the OracleResult-Class to keep everything tidy and clean.
# Labels for each input
oracle = [
OracleResult.BUG,
OracleResult.NO_BUG,
OracleResult.BUG,
OracleResult.NO_BUG,
OracleResult.NO_BUG,
OracleResult.NO_BUG,
OracleResult.NO_BUG
]
# Transform to numpy array
vec = DictVectorizer()
X = vec.fit_transform(features).toarray()
Using the feature array and labels, we can now train a decision tree classifier as follows:
# Fix the random state to produce a deterministic result (for illustration purposes only)
clf = DecisionTreeClassifier(random_state=10)
# sci-kit learn requires an array of strings
oracle_clean = [str(c) for c in oracle]
clf = clf.fit(X, oracle_clean)
Let's have a look at the learned decision tree:
def show_decision_tree(clf, feature_names):
dot_data = sklearn.tree.export_graphviz(clf, out_file=None,
feature_names=feature_names,
class_names=["BUG", "NO_BUG"],
filled=True, rounded=True)
return graphviz.Source(dot_data)
show_decision_tree(clf, vec.get_feature_names_out())

Here is a much reduced textual variant, still retaining the essential features:
def friendly_decision_tree(clf, feature_names,
class_names = ['NO_BUG', 'BUG'],
indent=0):
def _tree(index, indent):
s = ""
feature = clf.tree_.feature[index]
feature_name = feature_names[feature]
threshold = clf.tree_.threshold[index]
value = clf.tree_.value[index]
class_ = int(value[0][0])
class_name = class_names[class_]
left = clf.tree_.children_left[index]
right = clf.tree_.children_right[index]
if left == right:
# Leaf node
s += " " * indent + class_name + "\n"
else:
if math.isclose(threshold, 0.5):
s += " " * indent + f"if {feature_name}:\n"
s += _tree(right, indent + 2)
s += " " * indent + f"else:\n"
s += _tree(left, indent + 2)
else:
s += " " * indent + f"if {feature_name} <= {threshold:.4f}:\n"
s += _tree(left, indent + 2)
s += " " * indent + f"else:\n"
s += _tree(right, indent + 2)
return s
ROOT_INDEX = 0
return _tree(ROOT_INDEX, indent)
print(friendly_decision_tree(clf, vec.get_feature_names_out()))
if function-sqrt:
if number <= 13.0000:
BUG
else:
NO_BUG
else:
NO_BUG
We can see that our initial hypothesis is that the feature function-sqrt must be greater than 0.5 (i.e., present) and the feature number must be less or equal than 13 in order to produce a bug. The decision rule is not yet perfect, thus we need to refine our decision tree!
Learning a Decision Tree¶
For Alhazen's second step (Train Classification Model), we write a function train_tree(data) that trains a decision tree on a given data frame:
def train_tree(data: pandas.core.frame.DataFrame) -> sklearn.tree._classes.DecisionTreeClassifier
The function requires the following parameter:
- data: a
pandasdata frame containing the parsed and extracted features and the outcome of the executed input sample (oracle).
For instance, the data frame may look similar to this:
| feature_1 | feature_2 | ... | oracle |
|---|---|---|---|
| 1 | 0 | ... | 'BUG' |
| 0 | 1 | ... | 'NO_BUG' |
Note: Each row of data['oracle'] is of type OracleResult.
However, sci-kit learn requires an array of strings.
We have to convert them to learn the decision tree.
OUTPUT: the function returns a learned decision tree of type _sklearn.tree._classes.DecisionTreeClassifier_.
def train_tree(data):
sample_bug_count = len(data[(data["oracle"].astype(str) == "BUG")])
assert sample_bug_count > 0, "No bug samples found"
sample_count = len(data)
clf = DecisionTreeClassifier(min_samples_leaf=1,
min_samples_split=2, # minimal value
max_features=None,
max_depth=5, # max depth of the decision tree
class_weight={str("BUG"): (1.0/sample_bug_count),
str("NO_BUG"):
(1.0/(sample_count - sample_bug_count))})
clf = clf.fit(data.drop('oracle', axis=1), data['oracle'].astype(str))
# MARTIN: This is optional, but is a nice extesion that results in nicer decision trees
# clf = treetools.remove_infeasible(clf, features)
return clf
Step 3: Extract Feature Requirements¶
In this section, we will extract the learned features from the decision tree. Again, let us first test this manually on our calculator example.
# Features for each input, one dict per input
features = [
{'function-sqrt': 1, 'function-cos': 0, 'function-sin': 0, 'number': -900},
{'function-sqrt': 0, 'function-cos': 1, 'function-sin': 0, 'number': 300},
{'function-sqrt': 1, 'function-cos': 0, 'function-sin': 0, 'number': -1},
{'function-sqrt': 0, 'function-cos': 1, 'function-sin': 0, 'number': -10},
{'function-sqrt': 0, 'function-cos': 0, 'function-sin': 1, 'number': 36},
{'function-sqrt': 0, 'function-cos': 0, 'function-sin': 1, 'number': -58},
{'function-sqrt': 1, 'function-cos': 0, 'function-sin': 0, 'number': 27},
]
# Labels for each input
oracle = [
"BUG",
"NO_BUG",
"BUG",
"NO_BUG",
"NO_BUG",
"NO_BUG",
"NO_BUG"
]
# We can use the sklearn DictVectorizer to transform the features to numpy array:
# Notice: Use the correct labeling of the feature_names
# vec = DictVectorizer()
# X_vec = vec.fit_transform(features).toarray()
# feature_names = vec.get_feature_names_out()
# We can also use a pandas DataFrame and directly parse it to the decision tree learner
feature_names = ['function-sqrt', 'function-cos', 'function-sin', 'number']
X_data = pandas.DataFrame.from_records(features)
# Fix the random state to produce a deterministic result (for illustration purposes only)
clf = DecisionTreeClassifier(random_state=10)
# Train with DictVectorizer
# **Note:** The sklearn `DictVectorizer` uses an internal sort function as default. This will result in different feature_name indices. If you want to use the `Dictvectorizer` please ensure that you only access the feature_names with the function `vec.get_feature_names_out()`.
# We recommend that you use the `pandas` data frame, since this is also the format used in the feedback loop.
# clf = clf.fit(X_vec, oracle)
# Train with Pandas Dataframe
clf = clf.fit(X_data, oracle)
dot_data = sklearn.tree.export_graphviz(clf, out_file=None,
feature_names=feature_names,
class_names=["BUG", "NO BUG"],
filled=True, rounded=True)
graph = graphviz.Source(dot_data)
graph

print(friendly_decision_tree(clf, feature_names, class_names = ['NO_BUG', 'BUG']))
if function-sqrt:
if number <= 13.0000:
BUG
else:
NO_BUG
else:
NO_BUG
Step 4: Generating New Samples¶
The next step is to generate new samples. For this purpose, we negate the requirements on a path to refine and refute the decision tree.
Negating Requirements¶
First we will determine some boundaries to obtain better path negations.
x = pandas.DataFrame.from_records(features)
bounds = pandas.DataFrame([{'feature': c, 'min': x[c].min(), 'max': x[c].max()}
for c in feature_names],
columns=['feature', 'min', 'max']).set_index(['feature']).transpose()
We can use the function path.get(i).get_neg_ext(bounds) to obtain a negation for a single requirement on a path (indexed with i).
Let's verify if we can negate a whole path.
for count, path in enumerate(all_paths):
negated_string_path = path.get(0).get_neg_ext(bounds)[0]
for box_ in range(1, len(path)):
negated_string_path += " " + str(path.get(box_).get_neg_ext(bounds)[0])
print(f"Path {count}: {negated_string_path}, is_bug: {path.is_bug()}")
Path 0: function-sqrt > 0.5, is_bug: False Path 1: function-sqrt <= 0.5 number > 13.0, is_bug: True Path 2: function-sqrt <= 0.5 number <= 13.0, is_bug: False
Systematically Negating Paths¶
We will use the Decision tree and extract new input specifications to refine or refute our hypothesis (See Section 4.1 "Extracting Prediction Paths" in \cite{Kampmann2020}). These input specifications will be parsed to the input generator that tries to generate new inputs that fulfill the defined input specifications.
def extracting_prediction_paths(clf, feature_names, data):
# determine the bounds
bounds = pandas.DataFrame([{'feature': c, 'min': data[c].min(), 'max': data[c].max()}
for c in feature_names],
columns=['feature', 'min', 'max']).set_index(['feature']).transpose()
# go through tree leaf by leaf
all_reqs = set()
for path in tree_to_paths(clf, feature_names):
# generate conditions
for i in range(0, len(path)+1):
reqs_list = []
bins = format(i, "#0{}b".format(len(path)+2))[2:]
for p, b in zip(range(0, len(bins)), bins):
r = path.get(p)
if '1' == b:
reqs_list.append(r.get_neg_ext(bounds))
else:
reqs_list.append([r.get_str_ext()])
for reqs in all_combinations(reqs_list):
all_reqs.add(", ".join(sorted(reqs)))
return all_reqs
def all_combinations(reqs_lists):
result = [[]]
for reqs in reqs_lists:
t = []
for r in reqs:
for i in result:
t.append(i+[r])
result = t
return result
We will use the Decision tree and extract new input specifications to refine or refute our hypothesis (See paper Section 4.1 - Extracting Prediction Paths). These input specifications will be parsed to the input generator that tries to generate new inputs that fulfill the defined input specifications.
new_prediction_paths = extracting_prediction_paths(clf, feature_names, data=x)
for path in new_prediction_paths:
print(path)
function-sqrt <= 0.5, number <= 13.0 function-sqrt > 0.5 function-sqrt <= 0.5 function-sqrt <= 0.5, number > 13.0 function-sqrt > 0.5, number <= 13.0 function-sqrt > 0.5, number > 13.0
Input Specification Parser¶
Once we have input specifications, we must again extract them from the decision tree so we can interpret them.
SPEC_GRAMMAR: Grammar = {
"<start>":
["<req_list>"],
"<req_list>":
["<req>", "<req>"", ""<req_list>"],
"<req>":
["<feature>"" ""<quant>"" ""<num>"],
"<feature>": ["exists(<string>)",
"num(<string>)",
# currently not used
"char(<string>)",
"length(<string>)"],
"<quant>":
["<", ">", "<=", ">="],
"<num>": ["-<value>", "<value>"],
"<value>":
["<integer>.<integer>",
"<integer>"],
"<integer>":
["<digit><integer>", "<digit>"],
"<digit>":
["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"],
'<string>': ['<letters>'],
'<letters>': ['<letter><letters>', '<letter>'],
'<letter>': list(string.ascii_letters + string.digits + string.punctuation)
}
assert is_valid_grammar(SPEC_GRAMMAR)
Retrieving New input Specifications¶
The following classes represent requirements for the test cases to be generated.
class SpecRequirement:
'''
This class represents a requirement for a new input sample that should be generated.
This class contains the feature that should be fullfiled (Feature), a quantifier
("<", ">", "<=", ">=") and a value. For instance exist(feature) >= 0.5 states that
the syntactical existence feature should be used to produce a new input.
feature : Is the associated feature class
quant : The quantifier
value : The value of the requirement. Note that for existence features this value
is allways between 0 and 1.
'''
def __init__(self, feature: Feature, quantificator, value):
self.feature: Feature = feature
self.quant = quantificator
self.value = value
def __str__(self):
return f"Requirement({self.feature.name} {self.quant} {self.value})"
def __repr__(self):
return f"Requirement({self.feature.name}, {self.quant}, {self.value})"
def friendly(self):
def value(x):
try:
return float(x)
except Exception:
return None
if isinstance(self.feature, ExistenceFeature):
if value(self.value) > 0:
return f"{self.feature.friendly_name()}"
elif value(self.value) < 0:
return f"not {self.feature.friendly_name()}"
return f"{self.feature.friendly_name()} {self.quant} {self.value}"
class InputSpecification:
'''
This class represents a complete input specification of a new input. A input specification
consists of one or more requirements.
requirements : Is a list of all requirements that must be used.
'''
def __init__(self, requirements: List[SpecRequirement]):
self.requirements: List[SpecRequirement] = requirements
def __str__(self):
s = ", ".join(str(r) for r in self.requirements)
return f"InputSpecification({s})"
def friendly(self):
return " and ".join(r.friendly() for r in self.requirements)
def __repr__(self):
return self.__str__()
def get_all_subtrees(derivation_tree, non_terminal):
'''
Iteratively returns a list of subtrees that start with a given non_terminal.
'''
subtrees = []
(node, children) = derivation_tree
if node == non_terminal:
subtrees.append(derivation_tree)
for child in children:
subtrees = subtrees + get_all_subtrees(child, non_terminal)
return subtrees
def create_new_input_specification(derivation_tree, all_features) -> InputSpecification:
'''
This function creates a new input specification for a parsed decision tree path.
The input derivation_tree corresponds to a already negated path in the decision tree.
'''
requirement_list = []
for req in get_all_subtrees(derivation_tree, '<req>'):
feature_name = tree_to_string(get_all_subtrees(req, '<feature>')[0])
quant = tree_to_string(get_all_subtrees(req, '<quant>')[0])
value = tree_to_string(get_all_subtrees(req, '<num>')[0])
feature_class = None
for f in all_features:
if f.name == feature_name:
feature_class = f
requirement_list.append(SpecRequirement(feature_class, quant, value))
return InputSpecification(requirement_list)
def get_all_input_specifications(dec_tree,
all_features: List[Feature],
feature_names: List[str],
data) -> List[InputSpecification]:
'''
Returns a complete list new input specification that were extracted from a learned decision tree.
INPUT:
- dec_tree : The learned decision tree.
- all_features : A list of all features
- feature_names : The list of the feature names (feature.name)
- data. : The data that was used to learn the decision tree
OUTPUT:
- Returns a list of InputSpecifications
'''
prediction_paths = extracting_prediction_paths(dec_tree, feature_names, data)
input_specifications = []
# parse all extracted paths
for r in prediction_paths:
earley = EarleyParser(SPEC_GRAMMAR)
try:
for tree in earley.parse(r):
input_specifications.append(create_new_input_specification(tree, all_features))
except SyntaxError:
# Catch Parsing Syntax Errors: num(<term>) in [-900, 0] will fail; Might fix later
# For now, inputs following that form will be ignored
pass
return input_specifications
We implement a Grammar-Based Input Generator that generates new input samples from a List of InputSpecifications.
The input specifications are extracted from the decision tree boundaries in the previous Step 3: RequirementExtraction.
An InputSpecification consists of 1 to n many predicates or requirements (e.g. <feature> >= value, or num(<term>) <= 13).
We generate a new input for each InputSpecification.
The new input fulfills all the given requirements of an InputSpecification.
For further details, please refer to Section 4.4 and 4.5 of \cite{Kampmann2020} and the Chapter Efficient Grammar Fuzzing in the Fuzzing Book.
We define a function generate_samples() with the following input parameters:
grammar: the grammar used to produce new inputs (e.g. the CALCULATOR-Grammar)new_input_specification: a List of new inputs specifications (typeList[InputSpecification])timeout: a max time budget. Return the generated inputs when the time budget is exceeded.
The function returns a list of new inputs that are specified by the given input specifications.
def best_trees(forest, spec, grammar):
samples = [tree_to_string(tree) for tree in forest]
fulfilled_fractions= []
for sample in samples:
gen_features = collect_features([sample], grammar)
# calculate percentage of fulfilled requirements (used to rank the sample)
fulfilled_count = 0
total_count = len(spec.requirements)
for req in spec.requirements:
# for now, interpret requirement(exists(<...>) <= number) as false and requirement(exists(<...>) > number) as true
if isinstance(req.feature, ExistenceFeature):
expected = 1.0 if req.quant == '>' or req.quant == '>=' else 0.0
actual = gen_features[req.feature.name][0]
if actual == expected:
fulfilled_count += 1
else:
pass
# print(f'{req.feature} expected: {expected}, actual:{actual}')
elif isinstance(req.feature, NumericInterpretation):
expected_value = float(req.value)
actual_value = gen_features[req.feature.name][0]
fulfilled = False
if req.quant == '<':
fulfilled = actual_value < expected_value
elif req.quant == '<=':
fulfilled = actual_value <= expected_value
elif req.quant == '>':
fulfilled = actual_value > expected_value
elif req.quant == '>=':
fulfilled = actual_value >= expected_value
if fulfilled:
fulfilled_count += 1
else:
pass
# print(f'{req.feature} expected: {expected_value}, actual:{actual_value}')
fulfilled_fractions.append(fulfilled_count / total_count)
# print(f'Fraction of fulfilled requirements: {fulfilled_count / total_count}')
max_frac = max(fulfilled_fractions)
best_chosen = []
if max_frac == 1.0:
return True, forest[fulfilled_fractions.index(1.0)]
for i, t in enumerate(forest):
if fulfilled_fractions[i] == max_frac:
best_chosen.append(t)
return False, best_chosen
# well, not perfect and probably not very robust. but it works :)
def generate_samples_advanced(grammar: Grammar,
new_input_specifications: List[InputSpecification],
timeout: int) -> List[str]:
# if there are no input specifications: generate some random samples
if len(new_input_specifications) == 0:
fuzzer = GrammarFuzzer(grammar)
samples = [fuzzer.fuzz() for _ in range(100)]
return samples
final_samples = []
each_spec_timeout = timeout / len(new_input_specifications)
rhs_nonterminals = grammar.keys()# list(chain(*[nonterminals(expansion) for expansion in grammar[rule]]))
fuzzer = GrammarFuzzer(grammar)
for spec in new_input_specifications:
done = False
starttime = time.time()
best_chosen = [fuzzer.fuzz_tree() for _ in range(100)]
done, best_chosen = best_trees(best_chosen, spec, grammar)
if done:
final_samples.append(tree_to_string(best_chosen))
while not done and time.time() - starttime < each_spec_timeout:
# split in prefix, postfix and try to reach targets
for tree in best_chosen:
prefix_len = random.randint(1, 3)
curr = tree
valid = True
for i in range(prefix_len):
nt, children = curr
poss_desc_idxs = []
for c_idx, c in enumerate(children):
s, _ = c
possible_descend = s in rhs_nonterminals
if possible_descend:
poss_desc_idxs.append(c_idx)
if len(poss_desc_idxs) < 1:
valid = False
break
desc = random.randint(0, len(poss_desc_idxs) - 1)
curr = children[poss_desc_idxs[desc]]
if valid:
nt, _ = curr
for req in spec.requirements:
if isinstance(req.feature, NumericInterpretation) and nt == req.feature.key:
# hacky: generate a derivation tree for this numeric interpretation
hacky_grammar = copy.deepcopy(grammar)
hacky_grammar["<start>"] = [nt]
parser = EarleyParser(hacky_grammar)
try:
test = parser.parse(req.value)
x = list(test)[0]
_, s = x
# print(str(s[0]))
# replace curr in tree with this new tree
curr = s[0]
except SyntaxError:
pass
done, best_chosen = best_trees(best_chosen, spec, grammar)
if done:
final_samples.append(tree_to_string(best_chosen))
if not done:
final_samples.extend([tree_to_string(t) for t in best_chosen])
return final_samples
Here's another interesting generator function:
def generate_samples_random(grammar: Grammar,
new_input_specifications: List[InputSpecification],
timeout: int) -> List[str]:
f = GrammarFuzzer(grammar, max_nonterminals=50, log=False)
data = []
for _ in range(num):
new_input = f.fuzz()
data.append(new_input)
return data
This is what we use as default:
def generate_samples(grammar: Grammar,
new_input_specifications: List[InputSpecification],
timeout: int) -> List[str]:
# Could also be generate_samples_random()
return generate_samples_advanced(grammar, new_input_specifications, timeout)
Step 5: Executing New Inputs¶
We are almost done! All that is left is putting the above pieces together and create a loop around them.
The Alhazen Class¶
We implement a class Alhazen that serves as main entry point for our approach.
class Alhazen:
def __init__(self,
runner: Any,
grammar: Grammar,
initial_inputs: List[str], /,
verbose: bool = False,
max_iterations: int = 10,
generator_timeout: int = 10):
self._initial_inputs = initial_inputs
self._runner = runner
self._grammar = grammar
self._verbose = verbose
self._max_iter = max_iterations
self._previous_samples = None
self._data = None
self._trees = []
self._generator_timeout = generator_timeout
self._setup()
class Alhazen(Alhazen):
def _setup(self):
self._previous_samples = self._initial_inputs
self._all_features = extract_all_features(self._grammar)
self._feature_names = [f.name for f in self._all_features]
if self._verbose:
print("Features:", ", ".join(f.friendly_name()
for f in self._all_features))
class Alhazen(Alhazen):
def _add_new_data(self, exec_data, feature_data):
joined_data = exec_data.join(feature_data.drop(['sample'], axis=1))
# Only add valid data
new_data = joined_data[(joined_data['oracle'] != OracleResult.UNDEF)]
new_data = joined_data.drop(joined_data[joined_data.oracle.astype(str) == "UNDEF"].index)
if 0 != len(new_data):
if self._data is None:
self._data = new_data
else:
self._data = pandas.concat([self._data, new_data], sort=False)
class Alhazen(Alhazen):
def execute_samples(self, sample_list = None):
if sample_list is None:
sample_list = self._initial_inputs
data = []
for sample in sample_list:
result = self._runner(sample)
data.append({"oracle": result })
return pandas.DataFrame.from_records(data)
class Alhazen(Alhazen):
def run(self):
for iteration in range(1, self._max_iter + 1):
if self._verbose:
print(f"\nIteration #{iteration}")
self._iterate(self._previous_samples)
class Alhazen(Alhazen):
def all_trees(self, /, prune: bool = True):
trees = self._trees
if prune:
trees = [remove_unequal_decisions(tree) for tree in self._trees]
return trees
def last_tree(self, /, prune: bool = True):
return self.all_trees(prune=prune)[-1]
class Alhazen(Alhazen):
def _iterate(self, sample_list):
# Run samples, obtain test outcomes
exec_data = self.execute_samples(sample_list)
# Step 1: Extract features from the new samples
feature_data = collect_features(sample_list, self._grammar)
# Combine the new data with the already existing data
self._add_new_data(exec_data, feature_data)
# display(self._data)
# Step 2: Train the Decision Tree Classifier
dec_tree = train_tree(self._data)
self._trees.append(dec_tree)
if self._verbose:
print(" Decision Tree:")
all_features = extract_all_features(self._grammar)
all_feature_names = [f.friendly_name() for f in all_features]
print(friendly_decision_tree(dec_tree, all_feature_names, indent=4))
# Step 3: Extract new requirements from the tree
new_input_specifications = get_all_input_specifications(dec_tree,
self._all_features,
self._feature_names,
self._data.drop(['oracle'], axis=1))
if self._verbose:
print(f" New input specifications:")
for spec in new_input_specifications:
print(f" {spec.friendly()}")
# Step 4: Generate new inputs according to the new input specifications
new_samples = generate_samples(self._grammar,
new_input_specifications,
self._generator_timeout)
if self._verbose:
print(f" New samples:")
print(f" {', '.join(new_samples)}")
self._previous_samples = new_samples
class Alhazen(Alhazen):
def all_feature_names(self, friendly: bool = True) -> List[str]:
if friendly:
all_feature_names = [f.friendly_name() for f in self._all_features]
else:
all_feature_names = [f.name for f in self._all_features]
return all_feature_names
class Alhazen(Alhazen):
def show_decision_tree(self, tree = None, friendly: bool = True):
return show_decision_tree(tree or self.last_tree(),
self.all_feature_names())
class Alhazen(Alhazen):
def friendly_decision_tree(self, tree = None):
return friendly_decision_tree(tree or self.last_tree(),
self.all_feature_names())
A Sample Run¶
We can finally run Alhazen!
Set the number of refinement iterations and the timeout for the input generator. The execution time of Alhazen mainly depends on the number of iterations.
MAX_ITERATIONS = 20
GENERATOR_TIMEOUT = 10 # timeout in seconds
We initialize Alhazen with the previously used initial_sample_list:
initial_sample_list
['sqrt(-16)', 'sqrt(4)']
And here we go! When initialized with verbose=True, Alhazen prints its progress during execution, issuing for each iteration
- the last decision tree
- the new input specification resulting from the tree
- the new samples satisfying the input specification.
alhazen = Alhazen(sample_runner, CALC_GRAMMAR, initial_sample_list,
verbose=True,
max_iterations=MAX_ITERATIONS,
generator_timeout=GENERATOR_TIMEOUT)
alhazen.run()
Features: exists(<start>), <start> == '<function>(<term>)', exists(<function>), <function> == 'sqrt', <function> == 'tan', <function> == 'cos', <function> == 'sin', exists(<term>), <term> == '-<value>', <term> == '<value>', exists(<value>), <value> == '<integer>.<digits>', <value> == '<integer>', exists(<integer>), <integer> == '<lead-digit><digits>', <integer> == '<digit>', exists(<digits>), <digits> == '<digit><digits>', <digits> == '<digit>', exists(<lead-digit>), <lead-digit> == '1', <lead-digit> == '2', <lead-digit> == '3', <lead-digit> == '4', <lead-digit> == '5', <lead-digit> == '6', <lead-digit> == '7', <lead-digit> == '8', <lead-digit> == '9', exists(<digit>), <digit> == '0', <digit> == '1', <digit> == '2', <digit> == '3', <digit> == '4', <digit> == '5', <digit> == '6', <digit> == '7', <digit> == '8', <digit> == '9', <term>, <value>, <lead-digit>, <digit>, <digits>, <integer>
Iteration #1
Decision Tree:
if exists(<lead-digit>):
BUG
else:
NO_BUG
New input specifications:
exists(<lead-digit>)
exists(<lead-digit>)
New samples:
tan(85), sqrt(8.90)
Iteration #2
Decision Tree:
if <lead-digit> == '1':
BUG
else:
NO_BUG
New input specifications:
<lead-digit> == '1'
<lead-digit> == '1'
New samples:
sqrt(-8), sin(-123)
Iteration #3
Decision Tree:
if <digit> == '6':
BUG
else:
NO_BUG
New input specifications:
<digit> == '6'
<digit> == '6'
New samples:
sin(-17.6), sqrt(-9)
Iteration #4
Decision Tree:
if <digits> <= 6.5000:
if <term> == '<value>':
NO_BUG
else:
BUG
else:
NO_BUG
New input specifications:
<term> == '<value>' and <digits> <= 6.5
<term> == '<value>' and <digits> <= 6.5
<digits> <= 6.5
<digits> > 6.5
<term> == '<value>' and <digits> > 6.5
<term> == '<value>' and <digits> > 6.5
New samples:
tan(-94), sin(9.0), sin(95), cos(-96.87), tan(276), sqrt(-7441)
Iteration #5
Decision Tree:
if <lead-digit> == '1':
if <digits> <= 6.5000:
BUG
else:
NO_BUG
else:
NO_BUG
New input specifications:
<lead-digit> == '1' and <digits> > 6.5
<lead-digit> == '1' and <digits> <= 6.5
<lead-digit> == '1'
<lead-digit> == '1' and <digits> > 6.5
<lead-digit> == '1' and <digits> <= 6.5
<lead-digit> == '1'
New samples:
sqrt(148.3), tan(-64.0), sqrt(-7), cos(578.4776), sin(104), sqrt(190.5)
Iteration #6
Decision Tree:
if <digit> == '6':
if <function> == 'sqrt':
BUG
else:
NO_BUG
else:
NO_BUG
New input specifications:
<digit> == '6' and <function> == 'sqrt'
<digit> == '6' and <function> == 'sqrt'
<digit> == '6' and <function> == 'sqrt'
<digit> == '6' and <function> == 'sqrt'
<digit> == '6'
<digit> == '6'
New samples:
sqrt(-650.95), cos(-0.2), tan(47.6220551), sqrt(12.86), sqrt(-7.4), sqrt(56)
Iteration #7
Decision Tree:
if <lead-digit> <= 1.5000:
if <integer> <= 16.5000:
if <value> == '<integer>':
BUG
else:
NO_BUG
else:
if <digit> == '9':
NO_BUG
else:
NO_BUG
else:
if <digits> == '<digit>':
NO_BUG
else:
NO_BUG
New input specifications:
<value> == '<integer>' and <integer> > 16.5 and <lead-digit> <= 1.5
<value> == '<integer>' and <integer> > 16.5 and <lead-digit> > 1.5
<digit> == '9' and <integer> > 16.5 and <lead-digit> > 1.5
<value> == '<integer>' and <integer> <= 16.5 and <lead-digit> <= 1.5
<value> == '<integer>' and <integer> <= 16.5 and <lead-digit> <= 1.5
<digits> == '<digit>' and <lead-digit> > 1.5
<value> == '<integer>' and <integer> > 16.5 and <lead-digit> <= 1.5
<digit> == '9' and <integer> <= 16.5 and <lead-digit> > 1.5
<digits> == '<digit>' and <lead-digit> > 1.5
<value> == '<integer>' and <integer> <= 16.5 and <lead-digit> > 1.5
<digit> == '9' and <integer> > 16.5 and <lead-digit> <= 1.5
<digit> == '9' and <integer> <= 16.5 and <lead-digit> <= 1.5
<digit> == '9' and <integer> <= 16.5 and <lead-digit> > 1.5
<value> == '<integer>' and <integer> > 16.5 and <lead-digit> > 1.5
<digit> == '9' and <integer> > 16.5 and <lead-digit> > 1.5
<digit> == '9' and <integer> > 16.5 and <lead-digit> <= 1.5
<digits> == '<digit>' and <lead-digit> <= 1.5
<value> == '<integer>' and <integer> <= 16.5 and <lead-digit> > 1.5
<digits> == '<digit>' and <lead-digit> <= 1.5
<digit> == '9' and <integer> <= 16.5 and <lead-digit> <= 1.5
New samples:
sin(16338.11), sqrt(-90), sin(20.9), sin(14.4), sin(-16), sin(445.98), sqrt(164), sin(73.9), cos(4.929), sqrt(259), sqrt(-266.21529), sin(-31.96), sin(30.9), sin(-9.2), sqrt(-806.9), cos(-9), sqrt(-9.1), sin(0.94030), sin(8.09), cos(-596.0571795), cos(62.259), sqrt(-288965), sin(-9.158), tan(-5.89), cos(61507.92), cos(-429.7), cos(-944), sin(-315), sin(-41361.210), tan(-7838.7), sin(-55.14), cos(998.301326), tan(48.179), sin(59), cos(-45), sqrt(38.1), sqrt(8), sqrt(-0), cos(-84), tan(-9), tan(54), tan(66.8), sin(-1), sin(-98), tan(-0), sin(-48), cos(-269918), sqrt(-85.6), sin(364), sqrt(-7318), sqrt(35787261), sin(2), sin(5), sqrt(8), sqrt(9491), cos(-3), cos(-49.3), sin(-2), sin(3), sin(-5696.915), tan(51), cos(2), cos(744), sin(45), sin(2), cos(0), cos(6), tan(-87), tan(-1), tan(5), sin(-32.48), sqrt(-9), cos(26), sqrt(30.4), sqrt(-4), tan(-81), tan(-9), tan(-1), tan(651.76), cos(7), tan(-873), sqrt(8828), tan(7), sin(257), sqrt(4), cos(35.16), sqrt(8885.215), tan(-44.4), cos(-446.0), sin(-887), sin(-93.1), sin(-55.4), cos(-532.96), cos(3.851), cos(58.2), cos(9.32800576), cos(80.88), cos(-4.824837), cos(7.0), tan(94.9), sin(6.6), tan(97.20), tan(0.648), sqrt(-96.18), tan(-91.50), sqrt(7.472), tan(-4.10), cos(23.990), tan(65776.5), sin(-3.9), tan(-9.2), sin(-8.26), tan(-73907.302), sin(-401.8), cos(3395.460), tan(-1.5), sqrt(-63.3), sqrt(236903.75), tan(-5.2), sin(9.3), sin(-2.7), cos(99.9), tan(-81.70), tan(38.237), sin(-765.97), tan(-246.611), sqrt(28.2), sqrt(-36.7), cos(-272.68), tan(52699772746.0), sqrt(3.50), sin(866384.7), tan(4.1), cos(-0.123), tan(34.02), tan(-2.917), sin(48.60), cos(8.0), sin(-5.8), sqrt(-81.3), cos(5252.70), sqrt(-5.7), tan(989.723), tan(188), sin(13.6), sin(-84), sqrt(1), sin(1), sqrt(-95.20), sin(-33545), tan(-5.665), sqrt(-1), tan(488.3), tan(-6), tan(-7.172), sin(16), tan(-4555), cos(-6.431), tan(5), sin(-3), sqrt(-2), cos(23), sqrt(-0), sin(6), sin(-325), cos(-27), sin(0.3), sin(0), cos(-8.8), sqrt(-61), sin(-421), cos(-4), tan(6), cos(388), sin(775.84188), cos(-1), sin(-50), tan(-0.36), tan(-6), cos(80.241), tan(8), sin(-3), sqrt(10.7), tan(6.6), cos(75.1), cos(-81.73), sin(-8), cos(31.11), sqrt(14.882731), tan(43), cos(53), tan(34), sin(-31.5), sin(-6.2), tan(325.687), cos(0.034), cos(-6), sqrt(206.6), sin(-0), cos(12), sin(-4), sqrt(8430), tan(-33.4), tan(1.6), sqrt(-767523), tan(6.6), tan(677), sqrt(42.734), tan(0), sin(6), sin(-0), tan(0.40616), tan(6), cos(5.1010), tan(-0.300073), tan(2), cos(941.0), cos(-26), sqrt(-80.77), tan(-0.68), sin(-821), cos(-67088), tan(42.909), sqrt(-255), tan(193), sin(17813), tan(586), tan(-8), cos(5), tan(7), sin(64), cos(37), tan(-0), cos(9), tan(-7), tan(4), sqrt(-693), sqrt(-9550), sqrt(-5), sin(6), cos(-4), cos(608292), sin(-6), sqrt(-5), sqrt(-8), sin(-343), cos(-3), sqrt(94209), sqrt(-93), cos(-8), sin(-8), tan(-9), tan(35), sqrt(-8562), cos(0), sin(-2), tan(-0), cos(4), sqrt(-946), tan(-2), sqrt(6), cos(541678214), sqrt(-8), tan(6), sqrt(6), cos(3), cos(-44), sin(5), tan(-6), cos(92759), cos(437), sqrt(6), sin(18), sqrt(0), tan(9), sin(-6), sin(-5), sqrt(-5), cos(-5), sqrt(2), cos(4), cos(-125276.1), tan(-1243), tan(8), cos(1), sqrt(0), sin(4), sqrt(-0), tan(-9), tan(-8), sin(-8), sqrt(-8), tan(2), cos(-8), sqrt(14), sin(15682), sin(107.814), sin(-13), tan(1), cos(7), sin(-8), sqrt(-3), cos(-2), sin(-11.2), sin(-3), cos(7), sin(19.91), cos(6), tan(-4.028015985), cos(9), sin(-15), tan(9), cos(-9.3), sqrt(-1098), sin(-9), sqrt(-198.1), sin(4.80910), cos(129.8), sqrt(1921)
Iteration #8
Decision Tree:
if <lead-digit> <= 3.5000:
if <function> == 'sqrt':
if <digits> <= 7.5000:
if <term> <= -2.6500:
BUG
else:
NO_BUG
else:
if <lead-digit> == '1':
NO_BUG
else:
NO_BUG
else:
if <term> == '-<value>':
NO_BUG
else:
NO_BUG
else:
if <value> == '<integer>':
NO_BUG
else:
NO_BUG
New input specifications:
<function> == 'sqrt' and <term> == '-<value>' and <lead-digit> > 3.5
<function> == 'sqrt' and <digits> > 7.5 and <lead-digit> <= 3.5 and <term> <= -2.6500000953674316
<function> == 'sqrt' and <digits> > 7.5 and <lead-digit> > 3.5 and <term> > -2.6500000953674316
<function> == 'sqrt' and <lead-digit> == '1' and <digits> <= 7.5 and <lead-digit> > 3.5
<function> == 'sqrt' and <digits> <= 7.5 and <lead-digit> > 3.5 and <term> <= -2.6500000953674316
<function> == 'sqrt' and <lead-digit> == '1' and <digits> > 7.5 and <lead-digit> > 3.5
<function> == 'sqrt' and <digits> > 7.5 and <lead-digit> <= 3.5 and <term> > -2.6500000953674316
<function> == 'sqrt' and <lead-digit> == '1' and <digits> > 7.5 and <lead-digit> > 3.5
<value> == '<integer>' and <lead-digit> > 3.5
<value> == '<integer>' and <lead-digit> <= 3.5
<function> == 'sqrt' and <term> == '-<value>' and <lead-digit> <= 3.5
<function> == 'sqrt' and <lead-digit> == '1' and <digits> > 7.5 and <lead-digit> <= 3.5
<function> == 'sqrt' and <lead-digit> == '1' and <digits> <= 7.5 and <lead-digit> <= 3.5
<function> == 'sqrt' and <term> == '-<value>' and <lead-digit> > 3.5
<function> == 'sqrt' and <lead-digit> == '1' and <digits> > 7.5 and <lead-digit> <= 3.5
<function> == 'sqrt' and <lead-digit> == '1' and <digits> <= 7.5 and <lead-digit> > 3.5
<value> == '<integer>' and <lead-digit> <= 3.5
<function> == 'sqrt' and <term> == '-<value>' and <lead-digit> <= 3.5
<function> == 'sqrt' and <digits> > 7.5 and <lead-digit> > 3.5 and <term> <= -2.6500000953674316
<function> == 'sqrt' and <digits> <= 7.5 and <lead-digit> <= 3.5 and <term> > -2.6500000953674316
<function> == 'sqrt' and <digits> <= 7.5 and <lead-digit> <= 3.5 and <term> <= -2.6500000953674316
<function> == 'sqrt' and <lead-digit> == '1' and <digits> <= 7.5 and <lead-digit> <= 3.5
<function> == 'sqrt' and <digits> <= 7.5 and <lead-digit> > 3.5 and <term> > -2.6500000953674316
<value> == '<integer>' and <lead-digit> > 3.5
New samples:
cos(78), sqrt(-25334.88), sqrt(8348), sqrt(-45), sqrt(54.3), sqrt(-7144), cos(-65.5), sqrt(54.6), sin(-46), sqrt(-37.3), sqrt(-3.6), sqrt(939228811.2), sqrt(3768837.541), sqrt(686.293), sqrt(-969463), sqrt(-1730), sqrt(14.75), sqrt(-918), sqrt(656.7), sqrt(75878), sqrt(-19.8), sqrt(-79), sqrt(616371.7), sqrt(-41.033), cos(36), cos(-306.4), sqrt(-1598), sqrt(-24), tan(-623), sqrt(23832.3), sqrt(-53.3), sqrt(-57), sqrt(84.3), cos(14.5334), tan(342.0), sqrt(-63429923.1), sqrt(26), sqrt(-16), sqrt(17.04), sqrt(51), cos(-71)
Iteration #9
Decision Tree:
if <term> <= -15.5000:
if <integer> <= 42.5000:
if <function> == 'sqrt':
BUG
else:
if <digit> == '2':
NO_BUG
else:
NO_BUG
else:
NO_BUG
else:
NO_BUG
New input specifications:
<function> == 'sqrt' and <integer> > 42.5 and <term> <= -15.5
<function> == 'sqrt' and <integer> <= 42.5 and <term> <= -15.5
<term> > -15.5
<function> == 'sqrt' and <integer> > 42.5 and <term> > -15.5
<digit> == '2' and <function> == 'sqrt' and <integer> <= 42.5 and <term> <= -15.5
<digit> == '2' and <function> == 'sqrt' and <integer> <= 42.5 and <term> > -15.5
<integer> > 42.5 and <term> <= -15.5
<term> <= -15.5
<digit> == '2' and <function> == 'sqrt' and <integer> > 42.5 and <term> > -15.5
<digit> == '2' and <function> == 'sqrt' and <integer> > 42.5 and <term> > -15.5
<digit> == '2' and <function> == 'sqrt' and <integer> <= 42.5 and <term> > -15.5
<integer> > 42.5 and <term> > -15.5
<integer> <= 42.5 and <term> <= -15.5
<digit> == '2' and <function> == 'sqrt' and <integer> <= 42.5 and <term> <= -15.5
<digit> == '2' and <function> == 'sqrt' and <integer> > 42.5 and <term> <= -15.5
<function> == 'sqrt' and <integer> <= 42.5 and <term> > -15.5
<digit> == '2' and <function> == 'sqrt' and <integer> > 42.5 and <term> <= -15.5
New samples:
sqrt(-1145), tan(-21), tan(-20.0), sqrt(-0.48), sqrt(6), sqrt(-69), sqrt(-5.43), sqrt(-47), sqrt(6.3729394), sqrt(9), sqrt(40.7), cos(-18.4), sqrt(5), sqrt(-3.7), sqrt(0), sqrt(9.5), cos(-32.2), sin(5.6), sqrt(84), tan(-30), sin(-3.5), sqrt(-72), tan(-79), tan(97039207), tan(93), sin(-2.94), sin(82.2), tan(-33), cos(-32.35), sin(-57.6689), sqrt(6.6), cos(-62.71)
Iteration #10
Decision Tree:
if <term> <= -15.5000:
if <term> <= -42.5165:
if <digits>:
NO_BUG
else:
NO_BUG
else:
if <function> == 'sqrt':
BUG
else:
if <digit> == '3':
NO_BUG
else:
NO_BUG
else:
if <function> == 'sin':
NO_BUG
else:
NO_BUG
New input specifications:
<digits> > 0.5 and <term> <= -42.51650047302246
<function> == 'sin' and <term> <= -15.5
<digits> > 0.5 and <term> > -42.51650047302246
<digits> <= 0.5 and <term> <= -42.51650047302246
<function> == 'sin' and <term> > -15.5
<function> == 'sin' and <term> <= -15.5
<function> == 'sin' and <term> > -15.5
<digits> <= 0.5 and <term> > -42.51650047302246
New samples:
sin(-953), sin(-58), sin(-10.70546), cos(-75), tan(-342.8), sin(-74.2), sin(-47), tan(-5793.1), sqrt(-549), sin(-778), cos(-46), tan(-61), tan(-1847.7), tan(-506), tan(-611), sin(8.0), sin(2.868), sqrt(-14007), sqrt(37), sin(-40)
Iteration #11
Decision Tree:
if <term> <= -15.5000:
if <value> <= 42.5165:
if <function> == 'sqrt':
BUG
else:
NO_BUG
else:
NO_BUG
else:
NO_BUG
New input specifications:
<function> == 'sqrt' and <term> > -15.5 and <value> > 42.51650047302246
<function> == 'sqrt' and <term> <= -15.5 and <value> <= 42.51650047302246
<function> == 'sqrt' and <term> > -15.5 and <value> <= 42.51650047302246
<term> > -15.5
<term> <= -15.5
<term> <= -15.5 and <value> > 42.51650047302246
<function> == 'sqrt' and <term> <= -15.5 and <value> <= 42.51650047302246
<term> > -15.5 and <value> > 42.51650047302246
<function> == 'sqrt' and <term> <= -15.5 and <value> > 42.51650047302246
<function> == 'sqrt' and <term> <= -15.5 and <value> > 42.51650047302246
<function> == 'sqrt' and <term> > -15.5 and <value> > 42.51650047302246
<term> <= -15.5 and <value> <= 42.51650047302246
<function> == 'sqrt' and <term> > -15.5 and <value> <= 42.51650047302246
New samples:
sqrt(450.244), sqrt(-50), tan(-34.6), sqrt(9), sqrt(9), sqrt(-88.0), sqrt(-4.1), sqrt(7.02), sin(-19), sqrt(-39347.9), sqrt(4.0065), sqrt(6.9), sqrt(7.1), sqrt(15.5), cos(-25.795), sqrt(-291), sqrt(-1.92), sqrt(-1.9950), tan(-23), sqrt(8), sqrt(-3.9), sqrt(-422), sqrt(5), sin(-1.6176), tan(-1), sqrt(-60204.20), tan(-7172103), tan(-34.8), sqrt(5756.8), cos(-97), sqrt(-62.0), tan(77.7), sqrt(-21), sqrt(2.305)
Iteration #12
Decision Tree:
if <lead-digit> <= 4.5000:
if <function> == 'sqrt':
if <integer> <= 41.5000:
if <term> <= -2.6500:
BUG
else:
if <digit> == '1':
NO_BUG
else:
NO_BUG
else:
if <lead-digit> <= 1.5000:
NO_BUG
else:
NO_BUG
else:
if <lead-digit> == '1':
NO_BUG
else:
NO_BUG
else:
if <function> == 'sqrt':
NO_BUG
else:
NO_BUG
New input specifications:
<function> == 'sqrt' and <lead-digit> == '1' and <lead-digit> > 4.5
<digit> == '1' and <function> == 'sqrt' and <integer> > 41.5 and <lead-digit> <= 4.5 and <term> <= -2.6500000953674316
<function> == 'sqrt' and <lead-digit> == '1' and <lead-digit> > 4.5
<function> == 'sqrt' and <lead-digit> <= 4.5
<digit> == '1' and <function> == 'sqrt' and <integer> > 41.5 and <lead-digit> > 4.5 and <term> > -2.6500000953674316
<function> == 'sqrt' and <integer> <= 41.5 and <lead-digit> <= 4.5 and <term> > -2.6500000953674316
<function> == 'sqrt' and <lead-digit> > 4.5
<function> == 'sqrt' and <integer> <= 41.5 and <lead-digit> <= 4.5 and <term> <= -2.6500000953674316
<digit> == '1' and <function> == 'sqrt' and <integer> <= 41.5 and <lead-digit> <= 4.5 and <term> > -2.6500000953674316
<digit> == '1' and <function> == 'sqrt' and <integer> > 41.5 and <lead-digit> > 4.5 and <term> > -2.6500000953674316
<digit> == '1' and <function> == 'sqrt' and <integer> <= 41.5 and <lead-digit> <= 4.5 and <term> <= -2.6500000953674316
<digit> == '1' and <function> == 'sqrt' and <integer> > 41.5 and <lead-digit> <= 4.5 and <term> <= -2.6500000953674316
<function> == 'sqrt' and <lead-digit> == '1' and <lead-digit> <= 4.5
<function> == 'sqrt' and <integer> > 41.5 and <lead-digit> <= 4.5 and <term> <= -2.6500000953674316
<digit> == '1' and <function> == 'sqrt' and <integer> <= 41.5 and <lead-digit> > 4.5 and <term> > -2.6500000953674316
<function> == 'sqrt' and <integer> <= 41.5 and <lead-digit> <= 1.5
<digit> == '1' and <function> == 'sqrt' and <integer> > 41.5 and <lead-digit> <= 4.5 and <term> > -2.6500000953674316
<function> == 'sqrt' and <integer> > 41.5 and <lead-digit> <= 1.5
<function> == 'sqrt' and <integer> > 41.5 and <lead-digit> > 1.5
<function> == 'sqrt' and <lead-digit> == '1' and <lead-digit> <= 4.5
<digit> == '1' and <function> == 'sqrt' and <integer> <= 41.5 and <lead-digit> > 4.5 and <term> > -2.6500000953674316
<function> == 'sqrt' and <lead-digit> <= 4.5
<digit> == '1' and <function> == 'sqrt' and <integer> <= 41.5 and <lead-digit> <= 4.5 and <term> > -2.6500000953674316
<digit> == '1' and <function> == 'sqrt' and <integer> > 41.5 and <lead-digit> <= 4.5 and <term> > -2.6500000953674316
<function> == 'sqrt' and <lead-digit> > 4.5
<function> == 'sqrt' and <integer> <= 41.5 and <lead-digit> > 4.5 and <term> <= -2.6500000953674316
<function> == 'sqrt' and <integer> <= 41.5 and <lead-digit> > 1.5
<function> == 'sqrt' and <integer> > 41.5 and <lead-digit> > 4.5 and <term> <= -2.6500000953674316
<digit> == '1' and <function> == 'sqrt' and <integer> <= 41.5 and <lead-digit> <= 4.5 and <term> <= -2.6500000953674316
New samples:
sin(-98), sin(-3817456.3), sqrt(-71.5), cos(-4475.148), sqrt(-42), sqrt(-20096.4), sqrt(347.1), cos(56.4), cos(-17), sin(70), cos(-95.795), cos(120.3), tan(680), cos(-90.8), sin(522), tan(1248), sin(-51.918), cos(856.00), tan(619.7), tan(-7883), sin(-75), sqrt(269.50), sqrt(72.6), sqrt(34.88), sqrt(-6016.341), sqrt(-35), sqrt(9.86), sqrt(-29.593), cos(38), sqrt(2), sqrt(6.97), sqrt(-91.20471), tan(69.15), sqrt(-74673671), sqrt(97), tan(8346.8219), sqrt(97), sqrt(580.5), sqrt(-30.9), sqrt(-263), cos(36.1), sqrt(-377), sqrt(5228.4), sqrt(-2), sqrt(19), sqrt(9.8), sqrt(5), sqrt(8.83), sqrt(74), sqrt(5.55), sqrt(6), sqrt(-2), sqrt(6), sqrt(2), sqrt(2.5), sqrt(-12), sqrt(434), sqrt(578), sqrt(-13.5), sqrt(-258450.2), sqrt(58), sqrt(-201.5), sqrt(-19.14), cos(-141), sqrt(-300), sqrt(-18), cos(103.61), sin(-160), sqrt(-60.405), sqrt(-77110180), sin(-120.27), sqrt(9.3317), sqrt(-1), sqrt(5465.1), sqrt(1), cos(23), sqrt(31.04), sqrt(217), sin(-604.40), sqrt(-35), sqrt(-4.1), sqrt(-5.60), sqrt(-5771.08), sqrt(-769), sqrt(-7), sqrt(-54.7), sqrt(-61), sqrt(-80), sqrt(-35.7), sqrt(-99), sqrt(-38.34275)
Iteration #13
Decision Tree:
if <lead-digit> <= 4.5000:
if <function> == 'sqrt':
if <value> <= 42.3670:
if <term> == '-<value>':
if <digit> == '2':
BUG
else:
BUG
else:
NO_BUG
else:
if <value> <= 43.8670:
NO_BUG
else:
NO_BUG
else:
if <function> == 'sin':
NO_BUG
else:
NO_BUG
else:
if <lead-digit> == '9':
NO_BUG
else:
NO_BUG
New input specifications:
<function> == 'sqrt' and <term> == '-<value>' and <lead-digit> <= 4.5 and <value> <= 42.367000579833984
<digit> == '2' and <function> == 'sqrt' and <term> == '-<value>' and <lead-digit> > 4.5 and <value> <= 42.367000579833984
<function> == 'sqrt' and <function> == 'sin' and <lead-digit> > 4.5
<function> == 'sqrt' and <term> == '-<value>' and <lead-digit> <= 4.5 and <value> > 42.367000579833984
<digit> == '2' and <function> == 'sqrt' and <term> == '-<value>' and <lead-digit> <= 4.5 and <value> > 42.367000579833984
<function> == 'sqrt' and <function> == 'sin' and <lead-digit> <= 4.5
<digit> == '2' and <function> == 'sqrt' and <term> == '-<value>' and <lead-digit> <= 4.5 and <value> <= 42.367000579833984
<function> == 'sqrt' and <lead-digit> > 4.5 and <value> > 43.867000579833984
<lead-digit> == '9' and <lead-digit> > 4.5
<function> == 'sqrt' and <term> == '-<value>' and <lead-digit> > 4.5 and <value> <= 42.367000579833984
<function> == 'sqrt' and <lead-digit> <= 4.5 and <value> > 43.867000579833984
<function> == 'sqrt' and <term> == '-<value>' and <lead-digit> <= 4.5 and <value> <= 42.367000579833984
<lead-digit> == '9' and <lead-digit> > 4.5
<function> == 'sqrt' and <function> == 'sin' and <lead-digit> > 4.5
<function> == 'sqrt' and <term> == '-<value>' and <lead-digit> > 4.5 and <value> > 42.367000579833984
<lead-digit> == '9' and <lead-digit> <= 4.5
<digit> == '2' and <function> == 'sqrt' and <term> == '-<value>' and <lead-digit> > 4.5 and <value> <= 42.367000579833984
<function> == 'sqrt' and <lead-digit> <= 4.5 and <value> <= 43.867000579833984
<digit> == '2' and <function> == 'sqrt' and <term> == '-<value>' and <lead-digit> <= 4.5 and <value> <= 42.367000579833984
<digit> == '2' and <function> == 'sqrt' and <term> == '-<value>' and <lead-digit> > 4.5 and <value> > 42.367000579833984
<function> == 'sqrt' and <lead-digit> > 4.5 and <value> <= 43.867000579833984
<function> == 'sqrt' and <function> == 'sin' and <lead-digit> <= 4.5
<digit> == '2' and <function> == 'sqrt' and <term> == '-<value>' and <lead-digit> <= 4.5 and <value> > 42.367000579833984
<digit> == '2' and <function> == 'sqrt' and <term> == '-<value>' and <lead-digit> > 4.5 and <value> > 42.367000579833984
<lead-digit> == '9' and <lead-digit> <= 4.5
New samples:
sqrt(28), sqrt(-9.2901), sqrt(-2.49), sin(6330), sqrt(3544504515.2), sqrt(-273), cos(17.84), sqrt(-33), cos(-42), sqrt(548.2177), cos(-92), sqrt(97), sqrt(7), sqrt(72), sqrt(86), sqrt(4), sqrt(8.9), sqrt(1.2), sqrt(995), sqrt(6), sqrt(2.1), sqrt(7), sqrt(469), sqrt(-11.7), sqrt(-71), tan(902), sqrt(911), sqrt(-30962.7), cos(1106.2), tan(11192), sqrt(38.0), tan(-9682.25), sqrt(12.172), tan(19.6), sqrt(271), tan(-303.7), tan(-315.114), sqrt(99.2), tan(-1634), sqrt(-46.0), sin(-40.8056), cos(-3417265), tan(-32.1), sqrt(31872784.34), sqrt(-991.2299), cos(28), tan(-239.2), cos(40.44748), sin(-44), tan(948086), sin(-93.084), sqrt(-841907.14), sqrt(-5.43), sqrt(-7.5), sqrt(-7), sqrt(-1.80), sqrt(-935), sqrt(-3.585), sqrt(-3), sqrt(-5.4), sqrt(38.4), sqrt(-31.0), sqrt(-950), sqrt(1.4097), sqrt(-23), sqrt(-26), sqrt(-97.269), sqrt(1), sqrt(-19.8), sqrt(5.52), sqrt(4), sqrt(-702159.2), sqrt(1), sqrt(4), sqrt(5.2), sqrt(7.137), sqrt(1), sqrt(-3), sqrt(26), sqrt(833852.9), sqrt(8.45), sqrt(88.68), sqrt(72), sqrt(17), sin(30), sqrt(-11627.4333), sqrt(-96.26), sin(396.3)
Iteration #14
Decision Tree:
if <lead-digit> <= 4.5000:
if <function> == 'sqrt':
if <value> <= 42.3670:
if <term> <= -11.8500:
BUG
else:
if <digit> == '6':
NO_BUG
else:
NO_BUG
else:
if <digit> == '1':
NO_BUG
else:
NO_BUG
else:
if <function> == 'sin':
NO_BUG
else:
NO_BUG
else:
if <integer> == '<digit>':
NO_BUG
else:
NO_BUG
New input specifications:
<digit> == '6' and <function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -11.849999904632568 and <value> <= 42.367000579833984
<digit> == '1' and <function> == 'sqrt' and <lead-digit> > 4.5 and <value> > 42.367000579833984
<integer> == '<digit>' and <lead-digit> > 4.5
<integer> == '<digit>' and <lead-digit> > 4.5
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -11.849999904632568 and <value> <= 42.367000579833984
<function> == 'sqrt' and <function> == 'sin' and <lead-digit> > 4.5
<function> == 'sqrt' and <function> == 'sin' and <lead-digit> <= 4.5
<digit> == '6' and <function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -11.849999904632568 and <value> <= 42.367000579833984
<digit> == '1' and <function> == 'sqrt' and <lead-digit> <= 4.5 and <value> > 42.367000579833984
<function> == 'sqrt' and <function> == 'sin' and <lead-digit> > 4.5
<digit> == '1' and <function> == 'sqrt' and <lead-digit> > 4.5 and <value> <= 42.367000579833984
<digit> == '6' and <function> == 'sqrt' and <lead-digit> <= 4.5 and <term> > -11.849999904632568 and <value> <= 42.367000579833984
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> > -11.849999904632568 and <value> <= 42.367000579833984
<integer> == '<digit>' and <lead-digit> <= 4.5
<digit> == '6' and <function> == 'sqrt' and <lead-digit> > 4.5 and <term> > -11.849999904632568 and <value> > 42.367000579833984
<digit> == '6' and <function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -11.849999904632568 and <value> <= 42.367000579833984
<digit> == '6' and <function> == 'sqrt' and <lead-digit> > 4.5 and <term> > -11.849999904632568 and <value> > 42.367000579833984
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -11.849999904632568 and <value> > 42.367000579833984
<digit> == '1' and <function> == 'sqrt' and <lead-digit> <= 4.5 and <value> > 42.367000579833984
<digit> == '1' and <function> == 'sqrt' and <lead-digit> > 4.5 and <value> > 42.367000579833984
<digit> == '1' and <function> == 'sqrt' and <lead-digit> <= 4.5 and <value> <= 42.367000579833984
<digit> == '6' and <function> == 'sqrt' and <lead-digit> > 4.5 and <term> > -11.849999904632568 and <value> <= 42.367000579833984
<digit> == '1' and <function> == 'sqrt' and <lead-digit> <= 4.5 and <value> <= 42.367000579833984
<integer> == '<digit>' and <lead-digit> <= 4.5
<digit> == '1' and <function> == 'sqrt' and <lead-digit> > 4.5 and <value> <= 42.367000579833984
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -11.849999904632568 and <value> <= 42.367000579833984
<digit> == '6' and <function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -11.849999904632568 and <value> <= 42.367000579833984
<digit> == '6' and <function> == 'sqrt' and <lead-digit> <= 4.5 and <term> > -11.849999904632568 and <value> > 42.367000579833984
<function> == 'sqrt' and <function> == 'sin' and <lead-digit> <= 4.5
<digit> == '6' and <function> == 'sqrt' and <lead-digit> > 4.5 and <term> > -11.849999904632568 and <value> <= 42.367000579833984
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -11.849999904632568 and <value> > 42.367000579833984
<digit> == '6' and <function> == 'sqrt' and <lead-digit> <= 4.5 and <term> > -11.849999904632568 and <value> <= 42.367000579833984
<digit> == '6' and <function> == 'sqrt' and <lead-digit> <= 4.5 and <term> > -11.849999904632568 and <value> > 42.367000579833984
New samples:
sqrt(-51137508.17), sqrt(-87), sqrt(-90.3), sqrt(-15), sqrt(-70), sqrt(-9457), sin(-93), sqrt(-0), cos(99), tan(-7), sqrt(-7.821), sqrt(7.9), tan(67), sqrt(3.0), sqrt(537), tan(73), sqrt(699.1), sin(-9), sqrt(1.4), sqrt(-2), cos(68.62), tan(-82), sin(1), tan(-2.30558), tan(-50), tan(6), sqrt(4.224), tan(3), sqrt(-69), sin(607), cos(-9345.6), sin(-2.77), sqrt(7), tan(-77), sqrt(-0), cos(8), sqrt(4), sin(-9.2), sin(-2), sin(-7), tan(-8), sin(-6), tan(925.97293), sqrt(-9.7), sqrt(80), sin(-8.2), tan(605.54792), sin(6.181), cos(69.147647), sin(-8.6), cos(-2.118), cos(-88.5), cos(-5), tan(-69.490), sin(-0), sin(-6433), sqrt(-7.19), cos(1.4), tan(-4.1), sin(-781), tan(-7), tan(8), sqrt(7.56), sin(-5), sin(-5), tan(974.60), sqrt(-5.4), sin(-5.5028), tan(774), sqrt(-989.9154), tan(-9), cos(-94), tan(-8), cos(-2), sin(-3.41), sqrt(1.4), sin(-943.60), sqrt(55), sin(-83084), cos(-83.36), sqrt(9), sqrt(968), cos(-0), sin(5908), tan(-98), sin(-9), cos(-9.3), cos(5.17202), sin(73), tan(97), sqrt(-97.9), sqrt(-97), sqrt(-8467995767.3), sqrt(-57), sqrt(-53340), sin(616), cos(4895), sqrt(-16), sqrt(178), tan(-8172.7), sqrt(-950.1), sqrt(2.15), sqrt(2.7081587), sqrt(-513), sqrt(17.8), sqrt(4.9), sqrt(-23.3), sqrt(-0), sqrt(2944), sqrt(-4), sqrt(319.308), sqrt(2.8095), sqrt(460.88), sqrt(7.5682), sqrt(428.6), sqrt(-22.7), sqrt(314), sqrt(-7.716), sqrt(-22), sqrt(48497), cos(39.10419), sqrt(2), sqrt(-16.5), sqrt(-7), sqrt(1214), sin(34.5), tan(18.1), sqrt(-33), tan(98.86122), tan(9167.4), tan(54.06869), tan(-26), sqrt(-1), cos(17.77), sqrt(-83251.1), sqrt(8.51), tan(33), sqrt(-7), sqrt(-0), sqrt(5.452), sqrt(1.57), sqrt(9.8), sqrt(-48.6), sqrt(-53.8), sqrt(-7.83), sqrt(-71454.05), cos(-127.703), sqrt(-5), sqrt(-9), sqrt(-55), sqrt(8.50), sqrt(-4), sqrt(-3), sqrt(2), sqrt(-585), sqrt(-46.75), sqrt(9.4), sqrt(-5201.73), tan(-25321.8), sqrt(71.0), sqrt(-8104), sqrt(-272.1), sqrt(8017.8), sqrt(9.1), sqrt(3191), sqrt(37), cos(-41.7), sqrt(-28.5), sqrt(3.621), sqrt(6.1), sqrt(8698), sqrt(-6.651), sqrt(-2.65), sqrt(30), sqrt(27), sin(-3464.1), tan(0.533), sqrt(-22), tan(-1.2), cos(27.60), cos(7), sqrt(6.34), sqrt(7.7), tan(8.0), sqrt(2047), sin(2.54), sqrt(-4), cos(-5.4), tan(1.83205), sqrt(31), tan(204), sin(-434.2), cos(-7), cos(-40), sqrt(-5), cos(7), sin(6), cos(5.0), sqrt(6), sqrt(2640), tan(-4217.297), tan(-2), sin(0), tan(44), cos(-498), sqrt(-1), sin(-1.0), sqrt(25.5), tan(2), tan(-2), cos(-29), cos(-29803), sqrt(-0.81), sin(-11.68), sin(3), sin(3.845), sin(247), cos(24.2), sqrt(-0.9), sin(2.73), cos(-3), tan(-38), sqrt(-39), tan(-0), sqrt(-8), tan(-260.63), tan(2.9), cos(-8), cos(9.6582305), sqrt(1.7), tan(0), sqrt(-5.7), cos(8), tan(-36.35), tan(41112), sin(1782.1), sin(-9), cos(1.25), tan(-9), cos(-4), tan(-4.0), tan(-354), sqrt(4), sqrt(-0.8), sqrt(-6), cos(2), tan(-6.9), cos(-10.8), tan(4617.031), sqrt(-19), sqrt(-6.0974), sqrt(-7), sqrt(0.6), sqrt(-4.4587), sqrt(5), sqrt(7.7), sqrt(-3.8), sqrt(5.2), sqrt(82), sqrt(-7), sqrt(25), sqrt(-99), sqrt(-25), sqrt(-26), sqrt(376), sin(2836305), sqrt(0), sqrt(-4), sqrt(575.0), sqrt(5), sqrt(2.1378), sqrt(3), sqrt(-9.32), sqrt(6494), sqrt(0), sqrt(-0), sqrt(27.827), sqrt(-3.45), sqrt(1.113), sqrt(-44.064), sqrt(0.6), tan(28.6), sqrt(2.856), sqrt(-6), tan(29.7662), sqrt(44)
Iteration #15
Decision Tree:
if <term> <= -11.8500:
if <integer> <= 43.0000:
if <function> == 'sqrt':
BUG
else:
NO_BUG
else:
NO_BUG
else:
NO_BUG
New input specifications:
<function> == 'sqrt' and <integer> <= 43.0 and <term> <= -11.849999904632568
<function> == 'sqrt' and <integer> > 43.0 and <term> <= -11.849999904632568
<term> <= -11.849999904632568
<integer> > 43.0 and <term> > -11.849999904632568
<integer> > 43.0 and <term> <= -11.849999904632568
<integer> <= 43.0 and <term> <= -11.849999904632568
<function> == 'sqrt' and <integer> <= 43.0 and <term> <= -11.849999904632568
<function> == 'sqrt' and <integer> <= 43.0 and <term> > -11.849999904632568
<function> == 'sqrt' and <integer> > 43.0 and <term> > -11.849999904632568
<function> == 'sqrt' and <integer> > 43.0 and <term> > -11.849999904632568
<function> == 'sqrt' and <integer> > 43.0 and <term> <= -11.849999904632568
<function> == 'sqrt' and <integer> <= 43.0 and <term> > -11.849999904632568
<term> > -11.849999904632568
New samples:
sin(-13), sqrt(-67.52), sin(-7090), sin(88.8), sqrt(-888.67), sqrt(-27.242329), sqrt(-12), sin(18.097), sqrt(55.6), sin(94.1), sin(-97), sqrt(5), sin(-3.83)
Iteration #16
Decision Tree:
if <lead-digit> <= 4.5000:
if <function> == 'sqrt':
if <term> <= -11.8500:
if <value> <= 43.0320:
BUG
else:
if <digits> <= 2.5000:
NO_BUG
else:
NO_BUG
else:
if <lead-digit> == '1':
NO_BUG
else:
NO_BUG
else:
NO_BUG
else:
if <digit> == '3':
NO_BUG
else:
NO_BUG
New input specifications:
<function> == 'sqrt' and <lead-digit> == '1' and <lead-digit> > 4.5 and <term> <= -11.849999904632568
<function> == 'sqrt' and <lead-digit> <= 4.5
<function> == 'sqrt' and <digits> > 2.5 and <lead-digit> <= 4.5 and <term> <= -11.849999904632568 and <value> > 43.031999588012695
<function> == 'sqrt' and <lead-digit> == '1' and <lead-digit> <= 4.5 and <term> > -11.849999904632568
<function> == 'sqrt' and <lead-digit> == '1' and <lead-digit> > 4.5 and <term> > -11.849999904632568
<digit> == '3' and <lead-digit> > 4.5
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -11.849999904632568 and <value> <= 43.031999588012695
<digit> == '3' and <lead-digit> <= 4.5
<function> == 'sqrt' and <lead-digit> == '1' and <lead-digit> <= 4.5 and <term> > -11.849999904632568
<function> == 'sqrt' and <lead-digit> == '1' and <lead-digit> > 4.5 and <term> > -11.849999904632568
<function> == 'sqrt' and <digits> > 2.5 and <lead-digit> > 4.5 and <term> <= -11.849999904632568 and <value> > 43.031999588012695
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> > -11.849999904632568 and <value> <= 43.031999588012695
<function> == 'sqrt' and <lead-digit> == '1' and <lead-digit> <= 4.5 and <term> <= -11.849999904632568
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -11.849999904632568 and <value> > 43.031999588012695
<function> == 'sqrt' and <digits> > 2.5 and <lead-digit> <= 4.5 and <term> <= -11.849999904632568 and <value> <= 43.031999588012695
<function> == 'sqrt' and <digits> <= 2.5 and <lead-digit> <= 4.5 and <term> <= -11.849999904632568 and <value> > 43.031999588012695
<digit> == '3' and <lead-digit> > 4.5
<function> == 'sqrt' and <digits> <= 2.5 and <lead-digit> <= 4.5 and <term> <= -11.849999904632568 and <value> <= 43.031999588012695
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -11.849999904632568 and <value> <= 43.031999588012695
<function> == 'sqrt' and <lead-digit> == '1' and <lead-digit> <= 4.5 and <term> <= -11.849999904632568
<function> == 'sqrt' and <lead-digit> <= 4.5
<digit> == '3' and <lead-digit> <= 4.5
<function> == 'sqrt' and <digits> <= 2.5 and <lead-digit> > 4.5 and <term> <= -11.849999904632568 and <value> > 43.031999588012695
<function> == 'sqrt' and <lead-digit> > 4.5
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -11.849999904632568 and <value> > 43.031999588012695
<function> == 'sqrt' and <lead-digit> == '1' and <lead-digit> > 4.5 and <term> <= -11.849999904632568
New samples:
sqrt(-77), sqrt(3592172.4), sqrt(-4944), sqrt(15.40), sqrt(63), sqrt(7995), sqrt(91), sqrt(68.7), sqrt(9107), sqrt(52), cos(-9334345), sqrt(-577), sqrt(-22.251), tan(-31), sqrt(376), sqrt(63.92), sqrt(-76.0), sqrt(25), sqrt(163), tan(-19.09), sqrt(-40), sqrt(-48.20), sqrt(-38), sqrt(-81), tan(-66), sqrt(-299.9), sqrt(37), sqrt(8.2), sqrt(-22.913), sqrt(-217.3), tan(4970.845), cos(2339.493), sqrt(-51), cos(-94559.7648), sqrt(-9253.8), sqrt(-500749.93), sqrt(-94.9), sqrt(-19.32733), sqrt(-60395), sqrt(-580.03), sqrt(-57.2)
Iteration #17
Decision Tree:
if <lead-digit> <= 4.5000:
if <function> == 'sqrt':
if <term> <= -11.8500:
if <term> <= -43.0320:
NO_BUG
else:
BUG
else:
NO_BUG
else:
NO_BUG
else:
NO_BUG
New input specifications:
<lead-digit> <= 4.5
<function> == 'sqrt' and <lead-digit> <= 4.5
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> > -43.031999588012695
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> > -43.031999588012695
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -11.849999904632568
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -11.849999904632568
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -43.031999588012695
<lead-digit> > 4.5
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -43.031999588012695
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> > -11.849999904632568
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> > -11.849999904632568
<function> == 'sqrt' and <lead-digit> <= 4.5
<function> == 'sqrt' and <lead-digit> > 4.5
New samples:
tan(-30.48), sqrt(14.9), sqrt(1345), sqrt(7233.843), sqrt(-47), sqrt(-50.81), tan(-482.00), cos(-314), cos(-25891.3), sqrt(34), sqrt(49.857), sin(-153), sqrt(221), sqrt(-16.439), sqrt(-67.58), sqrt(-52), sqrt(113.4), sqrt(24), cos(-461929.7), cos(-584), sqrt(-84.39), sqrt(49.7), sqrt(90), cos(11.7), cos(9563.326)
Iteration #18
Decision Tree:
if <lead-digit> <= 4.5000:
if <function> == 'sqrt':
if <term> <= -11.8500:
if <value> <= 43.0320:
if <term> <= -41.5165:
BUG
else:
BUG
else:
NO_BUG
else:
NO_BUG
else:
NO_BUG
else:
NO_BUG
New input specifications:
<lead-digit> <= 4.5
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -41.51650047302246 and <value> <= 43.031999588012695
<function> == 'sqrt' and <lead-digit> <= 4.5
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -11.849999904632568 and <value> <= 43.031999588012695
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -11.849999904632568
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -11.849999904632568
<lead-digit> > 4.5
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -11.849999904632568 and <value> > 43.031999588012695
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> > -11.849999904632568 and <value> > 43.031999588012695
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -41.51650047302246 and <value> <= 43.031999588012695
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> > -11.849999904632568
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> > -41.51650047302246 and <value> <= 43.031999588012695
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> > -11.849999904632568
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -11.849999904632568 and <value> <= 43.031999588012695
<function> == 'sqrt' and <lead-digit> <= 4.5
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -41.51650047302246 and <value> > 43.031999588012695
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -41.51650047302246 and <value> > 43.031999588012695
<function> == 'sqrt' and <lead-digit> > 4.5
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -11.849999904632568 and <value> > 43.031999588012695
New samples:
cos(12.1), sqrt(-33), sqrt(-25.0), sqrt(-34), sqrt(-43.0), sqrt(-940), sqrt(-8048331.4), sqrt(-916), sqrt(-64.70), sqrt(-125.942), sqrt(-84), sqrt(71.4), cos(-46500), sqrt(-13), sin(-4918.9), cos(-329), sqrt(-20.35), sqrt(-875), sqrt(362490), tan(-263863), sin(-3455), sqrt(-59.548931), tan(-357.86292), tan(-49.582), sqrt(39470), sqrt(-35.65), sqrt(3566), sqrt(-43), sqrt(-81415), sqrt(-55909.0), sqrt(33), sqrt(41), sqrt(76), sqrt(-26.0), sin(-45.66), sqrt(-757.35), sqrt(-2773.9), sin(8081929), sqrt(-65.0429)
Iteration #19
Decision Tree:
if <lead-digit> <= 4.5000:
if <value> <= 42.3670:
if <term> <= -11.8500:
if <function> == 'sqrt':
BUG
else:
NO_BUG
else:
if <value> <= 10.7027:
NO_BUG
else:
NO_BUG
else:
if <digit> == '7':
NO_BUG
else:
NO_BUG
else:
if <value> == '<integer>':
NO_BUG
else:
NO_BUG
New input specifications:
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> > -11.849999904632568 and <value> <= 42.367000579833984
<lead-digit> > 4.5 and <term> > -11.849999904632568 and <value> > 10.70272970199585
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -11.849999904632568 and <value> <= 42.367000579833984
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -11.849999904632568 and <value> <= 42.367000579833984
<lead-digit> <= 4.5 and <term> > -11.849999904632568 and <value> <= 10.70272970199585
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -11.849999904632568 and <value> > 42.367000579833984
<value> == '<integer>' and <lead-digit> > 4.5
<lead-digit> > 4.5 and <term> > -11.849999904632568 and <value> <= 10.70272970199585
<digit> == '7' and <lead-digit> <= 4.5 and <value> <= 42.367000579833984
<digit> == '7' and <lead-digit> > 4.5 and <value> > 42.367000579833984
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -11.849999904632568 and <value> <= 42.367000579833984
<digit> == '7' and <lead-digit> <= 4.5 and <value> <= 42.367000579833984
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> > -11.849999904632568 and <value> <= 42.367000579833984
<value> == '<integer>' and <lead-digit> <= 4.5
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -11.849999904632568 and <value> > 42.367000579833984
<value> == '<integer>' and <lead-digit> > 4.5
<digit> == '7' and <lead-digit> <= 4.5 and <value> > 42.367000579833984
<lead-digit> <= 4.5 and <term> > -11.849999904632568 and <value> > 10.70272970199585
<value> == '<integer>' and <lead-digit> <= 4.5
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -11.849999904632568 and <value> <= 42.367000579833984
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -11.849999904632568 and <value> > 42.367000579833984
<digit> == '7' and <lead-digit> > 4.5 and <value> <= 42.367000579833984
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -11.849999904632568 and <value> > 42.367000579833984
<digit> == '7' and <lead-digit> > 4.5 and <value> <= 42.367000579833984
<digit> == '7' and <lead-digit> <= 4.5 and <value> > 42.367000579833984
<digit> == '7' and <lead-digit> > 4.5 and <value> > 42.367000579833984
New samples:
sin(27.7), sin(67.98), sqrt(-6290), sqrt(-72), sqrt(-652.2), sqrt(-87.1), cos(-22), tan(3.6), sqrt(9), tan(-7.3), sin(0.859890), cos(2054.8), sqrt(-1), sin(3), cos(6.6), sqrt(-4.991), sqrt(-4), tan(-7), cos(-7), sqrt(-3.6), sin(4.6), sqrt(8.79), tan(-3.9445), sqrt(-6.1), tan(-0), tan(3), tan(6.122), cos(42), cos(1), cos(-2), cos(-7.8), sin(-9), sqrt(7.36), cos(-7), tan(-5), cos(8.175), sqrt(2.01), tan(8.4), cos(273), sin(1452.3), sin(7), sin(-8), tan(-4.37), sin(8), sqrt(-5.6), sin(-0), cos(5.3280), sqrt(42.36), sin(8), tan(8), sqrt(-5), sqrt(-4), cos(-0.906), cos(-2.54), sqrt(0), sin(2), cos(13), sin(-4), sin(4), cos(4.2), cos(-6), sqrt(2), sin(125540), cos(-5), cos(2), sin(2), sqrt(-5.22), cos(4876.204), sqrt(5.7), sqrt(48), sqrt(20), sqrt(3.6), sqrt(5), sin(6.943), tan(32), cos(38921523.0), sqrt(1179), tan(2), sin(-49.35), sin(91.08), tan(9.52), cos(-3), cos(2), tan(6), tan(-3.5), sin(-3), cos(9.16), tan(64), cos(3.7), sin(5), tan(8.583), cos(-6.78), sqrt(-4.94), sin(8180), sqrt(7.4), cos(5.44), cos(-2), sin(2), tan(62), tan(1.7), sqrt(1.00), sin(862), cos(6.5447221), sin(2.5), cos(2), sqrt(-9.8), tan(704.7), sqrt(-7), sin(-7), tan(5), sqrt(-0.8), sin(-7.6), sin(869734), sqrt(63367), cos(3), sin(4.17), tan(-4.7), sin(1), sqrt(-6.1), sin(-3.0), sqrt(3.2), cos(-0.9), sqrt(-0), tan(9), cos(79.5), tan(-8), tan(4.17878), tan(6.7), tan(7113.8), cos(90), sqrt(-2.634), sin(4), sqrt(733), tan(84.27), sin(749), sqrt(-1), tan(-3.4), cos(740.49), cos(-5.4), sqrt(-4.0), sin(507.94), sin(-1.2), tan(-6.9), tan(2), cos(56.82), sin(1), tan(5), sqrt(-1), sqrt(0), sin(-9.91), tan(90.7), tan(-6.7), sin(5), sin(16.2), sin(699.7), cos(-76), tan(-54.034), sin(-25), tan(-528), tan(-20), cos(-6814.5), tan(-9664.5), tan(-30), sin(-63), sin(-50), tan(-62.3), cos(-59.6), tan(-886.62), sqrt(-17.45153), sqrt(39), sin(337.2), sqrt(-59.7), sqrt(-5828), cos(-23297.404), cos(15.29), sqrt(-14), sqrt(-33), sin(-70.9266), sqrt(2), cos(-4), cos(4.5), cos(6.8), sin(0), sin(66.8), sqrt(-502.9), cos(65450.0), tan(-6), sin(0.5), tan(-4), cos(-9.41), sin(54), cos(-63099569.32), sin(83.3), sqrt(8), sqrt(-3), sqrt(5.20401), sin(88), tan(1), sin(-9), sqrt(-6), sin(-58), tan(3), sin(0), cos(-3), sin(-4), sin(2.4), sin(-1), tan(74.8), sin(3), sin(2.8), tan(-59), tan(5), tan(-8.1), sqrt(-5.9192), cos(-91.10), sqrt(-4), sin(-0), cos(6.8180), sin(9.36560908), sin(73), sin(-19.6), sqrt(-4.8), tan(5238.38), tan(52), sqrt(-9.2), sqrt(-2.9), cos(0.3), sqrt(85.8546), tan(-2), cos(68.53), cos(0), sin(3.5), tan(3.2), cos(-20), cos(6), sin(9.4), sqrt(-2), sqrt(-0.35662), sqrt(-5.52), tan(64113), sqrt(52.14), cos(8.0), cos(-5), cos(3), sqrt(-1), tan(-8), cos(-11), tan(-1), sqrt(-1037.25), sin(58.7), sin(-2.7744462), cos(52.07), cos(77), sqrt(-63.7), cos(-603.3067), sin(-9.87125), cos(-7.61), tan(-0.73), cos(-7), tan(-517.73), sqrt(-5427.4), tan(7), sqrt(2.57), sqrt(-739.438765), cos(-7.499), sqrt(-7.291), sin(67974279.41), sqrt(9867.7), sin(-7.177), sin(8.071326), tan(-7.723), cos(25.57), sin(887.3), sqrt(7.49), cos(-4505), sin(-760.19)
Iteration #20
Decision Tree:
if <lead-digit> <= 4.5000:
if <function> == 'sqrt':
if <term> <= -11.8500:
if <integer> <= 42.5000:
BUG
else:
NO_BUG
else:
NO_BUG
else:
NO_BUG
else:
NO_BUG
New input specifications:
<lead-digit> <= 4.5
<lead-digit> > 4.5
<function> == 'sqrt' and <integer> > 42.5 and <lead-digit> <= 4.5 and <term> <= -11.849999904632568
<function> == 'sqrt' and <integer> <= 42.5 and <lead-digit> <= 4.5 and <term> <= -11.849999904632568
<function> == 'sqrt' and <integer> > 42.5 and <lead-digit> > 4.5 and <term> <= -11.849999904632568
<function> == 'sqrt' and <lead-digit> <= 4.5
<function> == 'sqrt' and <integer> > 42.5 and <lead-digit> <= 4.5 and <term> > -11.849999904632568
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> > -11.849999904632568
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> > -11.849999904632568
<function> == 'sqrt' and <lead-digit> <= 4.5
<function> == 'sqrt' and <integer> <= 42.5 and <lead-digit> > 4.5 and <term> <= -11.849999904632568
<function> == 'sqrt' and <lead-digit> > 4.5
<function> == 'sqrt' and <lead-digit> <= 4.5 and <term> <= -11.849999904632568
<function> == 'sqrt' and <lead-digit> > 4.5 and <term> <= -11.849999904632568
<function> == 'sqrt' and <integer> <= 42.5 and <lead-digit> <= 4.5 and <term> > -11.849999904632568
New samples:
sqrt(-15.5), sin(6986), sqrt(-44.843), sqrt(-16), sqrt(-62.5), cos(-314.4), sqrt(52.1779), sqrt(83.5849), sqrt(29.3), sqrt(-1497272), cos(1385.83093), sqrt(10.98104), tan(2744.4), sqrt(11.5), cos(4706), tan(46265), sqrt(48), sqrt(63), sqrt(41), sqrt(-545), sqrt(-9320.680), sqrt(-80.65), sqrt(-87), sin(97159.2), sqrt(-428), sqrt(-50.9), sqrt(11)
To access the final decision tree learned by Alhazen, use:
alhazen.last_tree()
DecisionTreeClassifier(class_weight={'BUG': 0.01818181818181818,
'NO_BUG': 0.0007836990595611285},
max_depth=5)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeClassifier(class_weight={'BUG': 0.01818181818181818,
'NO_BUG': 0.0007836990595611285},
max_depth=5)Let's display it:
alhazen.show_decision_tree()

We can also view the tree as text:
print(alhazen.friendly_decision_tree())
if <lead-digit> <= 4.5000:
if <function> == 'sqrt':
if <term> <= -11.8500:
if <integer> <= 42.5000:
BUG
else:
NO_BUG
else:
NO_BUG
else:
NO_BUG
else:
NO_BUG
In both views, we see that the failure is related to the sqrt() function being called with a negative value.
But what's the deal with the <lead-digit> and <value> fields?
For this, let's have a look at our sqrt function code:
print(inspect.getsource(task_sqrt))
def task_sqrt(x):
"""Computes the square root of x, using the Newton-Raphson method"""
if x <= -12 and x >= -42:
x = 0 # Guess where the bug is :-)
else:
x = 1
x = max(x, 0)
approx = None
guess = x / 2
while approx != guess:
approx = guess
guess = (approx + x / approx) / 2
return approx
We see that Alhazen has correctly determined the boundaries of x for the bug - the <lead-digit> value must be 4 or less (otherwise, the value of x will not trigger the bug); and <value> and <term> correctly reflect the boundaries.
(Note that <term> comes with a sign, whereas <value> has no sign.)
Not too bad for a machine learning approach :-)
Synopsis¶
This chapter provides an implementation of the Alhazen approach \cite{Kampmann2020}, which trains machine learning classifiers from input features.
Given a test function, a grammar, and a set of inputs, the Alhazen class produces a decision tree that characterizes failure circumstances:
alhazen = Alhazen(sample_runner, CALC_GRAMMAR, initial_sample_list,
max_iterations=20)
alhazen.run()
The final decision tree can be accessed using last_tree():
# alhazen.last_tree()
We can visualize the resulting decision tree using Alhazen.show_decision_tree():
alhazen.show_decision_tree()

A decision tree is read from top to bottom. Decision nodes (with two children) come with a predicate on top. This predicate is either
- numeric, such as
<value> > 20, indicating the numeric value of the given symbol, or - existential, such as
<digit> == '1', which has a negative value when False, and a positive value when True.
If the predicate evaluates to True, follow the left path; if it evaluates to False, follow the right path.
A leaf node (no children) will give you the final decision class = BUG or class = NO_BUG.
So if the predicate states <function> == 'sqrt' <= 0.5, this means that
- If the function is not
sqrt(the predicate<function> == 'sqrt'is negative, see above, and hence less than 0.5), follow the left (True) path. - If the function is
sqrt(the predicate<function> == 'sqrt'is positive), follow the right (False) path.
The samples field shows the number of sample inputs that contributed to this decision.
The gini field (aka Gini impurity) indicates how many samples fall into the displayed class (BUG or NO_BUG).
A gini value of 0.0 means purity - all samples fall into the displayed class.
The saturation of nodes also indicates purity – the higher the saturation, the higher the purity.
There is also a text version available, with much fewer (but hopefully still essential) details:
print(alhazen.friendly_decision_tree())
if <lead-digit> <= 4.5000:
if <function> == 'sqrt':
if <value> <= 42.7000:
if <term> <= -11.7870:
BUG
else:
NO_BUG
else:
NO_BUG
else:
NO_BUG
else:
NO_BUG
In both representations, we see that the present failure is associated with a negative value for the sqrt function and precise boundaries for its value.
In fact, the error conditions are given in the source code:
print(inspect.getsource(task_sqrt))
def task_sqrt(x):
"""Computes the square root of x, using the Newton-Raphson method"""
if x <= -12 and x >= -42:
x = 0 # Guess where the bug is :-)
else:
x = 1
x = max(x, 0)
approx = None
guess = x / 2
while approx != guess:
approx = guess
guess = (approx + x / approx) / 2
return approx
Try out Alhazen on your own code and your own examples!
Lessons Learned¶
- Training machine learners from input features can give important insights on failure circumstances.
- Generating additional inputs based on feedback from the machine learner can greatly enhance precision.
- Applying machine learners on input and execution features is still at its infancy.
Next Steps¶
Our next chapter introduces automated repair of programs, building on the fault localization and generalization mechanisms introduced so far.
Background¶
This chapter is built on the Alhazen paper by Kampmann et al. \cite{Kampmann2020}.
In \cite{Eberlein2023}, Eberlein et al. introduced Avicenna, a new interpretation of Alhazen that makes use of the ISLa framework \cite{Steinhoefel2022} to learn and produce input features. Avicenna improves over Alhazen in terms of performance, expressiveness, and precision.